Introducing modm-devices: hardware descriptions for AVR and STM32 devices
For the last 2 years Fabian Greif and I have been working on a secret project called modm: a toolkit for data-driven code generation. In a nutshell, we feed detailed hardware description data for almost all AVR and STM32 targets into a code generator to create a C++ Hardware Abstraction Layer (HAL), startup & linkerscript code, documentation and support tools.
This isn’t exactly a new idea, after all very similar ideas have been floating around before, most notably in the Linux Kernel with its Device Tree (DT) effort. In fact, modm itself is based entirely on xpcc which matured the idea of data-driven HAL generation in the first place.
However, for modm we focused on what goes on behind the scenes: how to acquire detailed target description data and how to use it with reasonable effort. We now have a toolbox that transcends its use as our C++ HAL generator and instead can be applied generically to any project in any language (*awkwardly winks at the Rust community*). That’s pretty powerful stuff.
So let me first ease you into this topic with some historic background and then walk you through the data sources we use and the design decisions of our data engine. All with plenty of examples for you to follow along, just stay well clear of those hairy yaks in the distance.
The Origin Story
All the usual suspects in this case were members of the Roboterclub Aachen e. V. (@RCA_eV). Around 2006 the team surrounding Fabian had built a communication library called RCCP for doing remote procedure calls over CAN. Back then the only affordable microcontrollers were AVRs, but neither were they powerful enough to perform all the computations needed for autonomy nor did they have enough pins to interface with all the motors and sensors we stuffed in our robots. So an embedded PC programmed in various languages did all the heavy lifting and talked via CAN to the AVR actuators and sensors.
(It has been passed on for many generations of robot builders, that the embedded PC did a disk check once during its boot process, which rendered the robot unresponsive for a few minutes. Unfortunately it did this during the a Eurobot finals game and we lost due to that. Since then our robots don’t have a kernel in their critical path anymore.)
RCCP was eventually refactored into the Cross Platform Component Communication (XPCC) library and open-sourced on Sourceforge in 2009. Around 2012 when Fabian was leaving us to go work on satellites at the German space agency (DLR), I took over stewardship of the project and moved it over to GitHub where it exists to this day. It’s the foundation of all the RCAs robots.
From AVR to STM32
By the time I joined in 2010, the team had been using C++ on AVRs for years. Around 2012 we finally outgrew the AVRs used to control our autonomous robots and switched over to Arm Cortex-M devices, specifically the STM32 series. So began the cumbersome task of porting the HAL that worked so well on the AVRs to the STM32F1 and F4 families, both of which have much more capable peripherals.
We had inherited a C++ API that passed around static classes containing the peripheral abstraction to template classes wrapping these classes. It’s the clear anti-thesis of polymorphic interface design, almost a form of “compile time duck-typing”:
class GpioB0 {
public: // one class for every GPIO on the device
static void set(bool state);
};
class SpiMaster0 {
public: // one class for every Spi peripheral
static uint8_t swap(uint8_t data);
};
template< class SpiMaster, class ChipSelect >
class SensorDriver {
public:
uint8_t read() {
ChipSelect::set(Gpio::Low);
uint8_t result = SpiMaster::swap(foobar);
ChipSelect::set(Gpio::High);
return result;
}
};
// Hey look, a generic sensor driver
SensorDriver< SpiMaster0, GpioB0 > compass;
uint8_t heading = compass.read();
C++ concepts sure would be useful here for asserting SpiMaster traits. *cough*
This technique resulted in a rather unusual HAL, but when used in moderation it yields ridiculously small binary sizes! And this was absolutely a requirement on our AVRs which wanted to stuff full of control code for our autonomous robots.
The size reduction didn’t so much come from using C++ features like templates, but from being able to very accurately dissect special cases into their own functions. This is particularly useful on AVRs where the IO memory map is very irregular and differs quite a bit between devices. Writing one function to handle all variations at runtime can be more expensive than writing a couple of specialized functions and letting the linker throw away all the unused ones.
But it does have one significant and obvious disadvantage: Our HAL had to have a class for every peripheral you want to use. And adding these classes manually didn’t scale very well with us and it proved an even bigger problem for a device with the peripheral amount and features of an STM32. And so the inevitable happened: we started using preprocessor macros to “instantiate” these peripheral classes, or switched between different implementation with extensive, often nested, #if/#else/#endif trees. It was such an ugly solution.
We also had a mechanism for generating code manually calling a Jinja2 template engine and committing the result, in fact, already since Nov. 2009. It was first used to create the AVR’s UART classes and slowly expanded to other platforms. But it didn’t really scale either because you still had to explicitly provide all the substitution data to the engine, which usually only was the number, or letter, identifying the peripheral.
It wasn’t until 2013 that Kevin Läufer generalized this idea by moving it into our SCons-based build system and collecting all template substitution data into one common file per target, which we just called “The Device File” (naming things is hard, ok?). This made it much easier to generate new peripheral drivers and it even did so on-the-fly during the build process due to being included into SCons’ dependency graph, which eliminated the need for manually committing these generated files and keeping them up-to-date.
First Steps
The first draft of the STM32F407’s device file was assembled by hand and lacked a clear structure. In retrospect, we also had trouble deciding which data goes in the device file and which stays embedded in the templates, but, we didn’t sweat the details, since we had an entire library to refactor and a robot to build.
The major limitation of our system of course was getting the required data and manually assembling it didn’t scale, and so we were stuck in the same bottleneck as before, albeit with a slightly better build process. And then, after researching how avr-gcc actually generate the <avr/io.h> headers, a solution presented itself: Atmel publishes a bunch of XML files called Part Description Files, or PDFs (lolwut?), containing the memory map of their AVR devices, and we just had to reformat this a little bit. Right? If only I knew what I was getting into…
<module name="USART">
<instance name="USART0" caption="USART">
<register-group name="USART0" name-in-module="USART0" offset="0x00" address-space="data" caption="USART"/>
<signals>
<signal group="TXD" function="default" pad="PD1"/>
<signal group="RXD" function="default" pad="PD0"/>
<signal group="XCK" function="default" pad="PD4"/>
</signals>
</instance>
</module>
<module name="TWI">
<instance name="TWI" caption="Two Wire Serial Interface">
<register-group name="TWI" name-in-module="TWI" offset="0x00" address-space="data" caption="Two Wire Serial Interface"/>
<signals>
<signal group="SDA" function="default" pad="PC4"/>
<signal group="SCL" function="default" pad="PC5"/>
</signals>
</instance>
</module>
<module name="PORT">
<instance name="PORTB" caption="I/O Port">
<register-group name="PORTB" name-in-module="PORTB" offset="0x00" address-space="data" caption="I/O Port"/>
<signals>
<signal group="P" function="default" pad="PB0" index="0"/>
<signal group="P" function="default" pad="PB1" index="1"/>
<signal group="P" function="default" pad="PB2" index="2"/>
<signal group="P" function="default" pad="PB3" index="3"/>
<signal group="P" function="default" pad="PB4" index="4"/>
<signal group="P" function="default" pad="PB5" index="5"/>
<signal group="P" function="default" pad="PB6" index="6"/>
<signal group="P" function="default" pad="PB7" index="7"/>
</signals>
</instance>
Excerpt of the ATmega328P.atdf part description file.
It really turned out to be a great, but very much incomplete, source of information about AVRs. Even today, over 4 years later, 110 AVR memory maps are still missing GPIO signal definitions. So I did what any student with too much time on their hands would do: I began to manually assemble the missing information by downloading all existing AVR device datasheets, reading through all of them and collecting the pinouts in a spreadsheet. I then manually reformatted this data into a Python data structure, where it still exists today. Don’t do this! I did get the job done, but I wasted two weeks of my life with this crap and even though I was being really diligent, I still made a lot of mistakes.
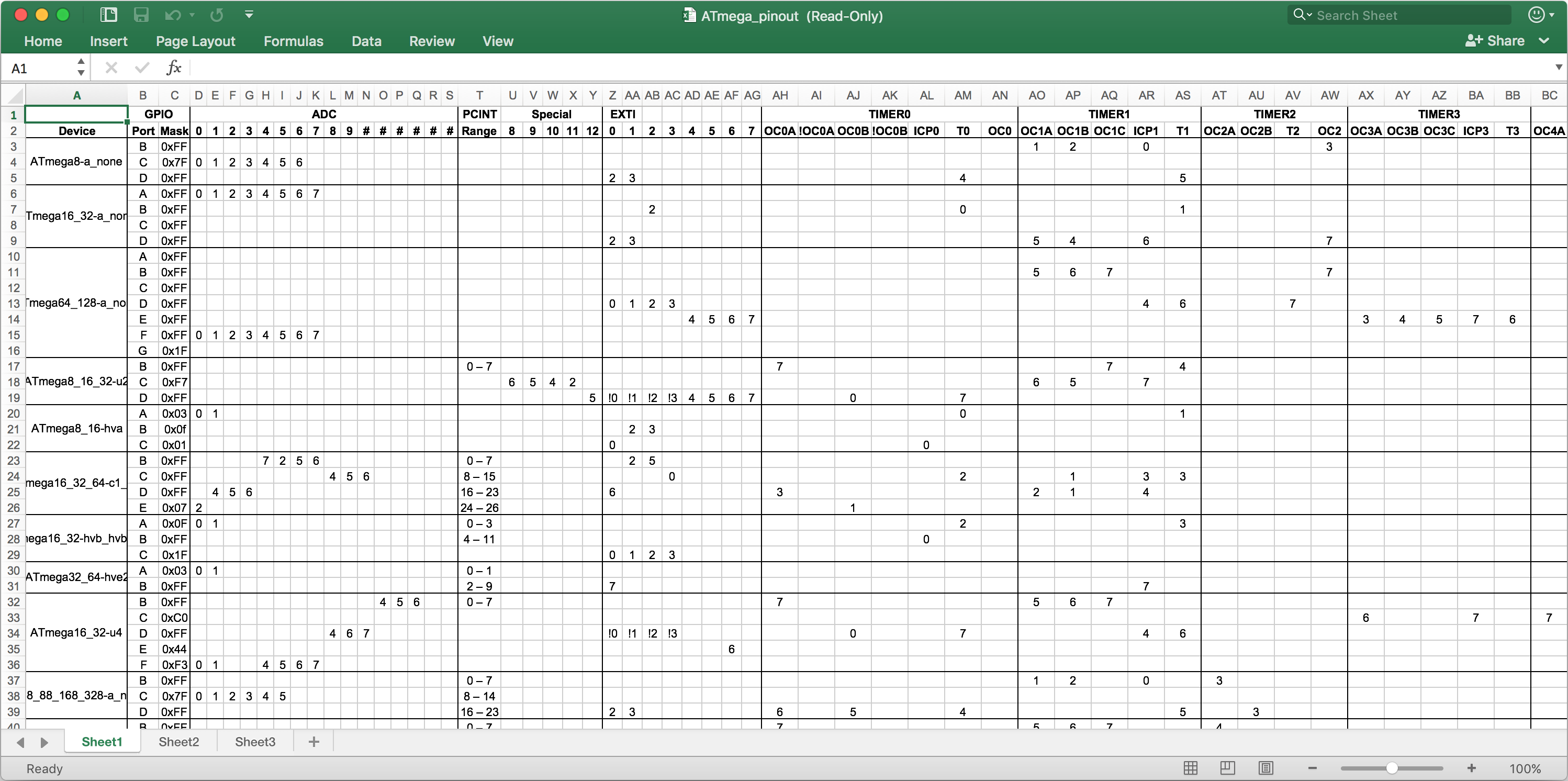
Ah, the insanities of youth 🙄
I also wrote a memory map comparison tool, which was really useful for understanding the batshit-insane AVR IO maps. Since the AVR can only address a certain amount of IO memory directly, the hardware engineers have to “compress” (more like “forcefully stuff”) the IO map and this quickly becomes very ugly. For example, the ATtiny*61 series features differential ADC inputs with selectable gains, configurable in 64 combinations, but register ADMUX only has space for 5 bits (MUX0 - MUX4). So Atmel decided to cram MUX5 into register ADCSRB:

Wait, did the ADLAR bit just move around? Nah, must be an illusion. 😒
This memory map comparison tool was vital in understanding how all the AVRs memory maps differ and coming up with strategies on how to map this functionality into our HAL. It’s all about tools, tools, tools, tools!
Peeking into STM32CubeMX
ST maintains the CubeMX initialization code generator, which contains “a pinout-conflict solver, a clock-tree setting helper, a power-consumption calculator, and an utility performing MCU peripheral configuration”. Hm, doesn’t that sound interesting? How did they implement these features, we wondered.
Back in 2013 CubeMX was still called MicroXplorer and wasn’t nearly as nice to use as today. It also launched as a Windows-only application, even though it was clearly written in Java (those “beautiful” GUI elements give it away). Nevertheless, CubeMX indeed is a very useful application, giving you a number of visual configuration editors:
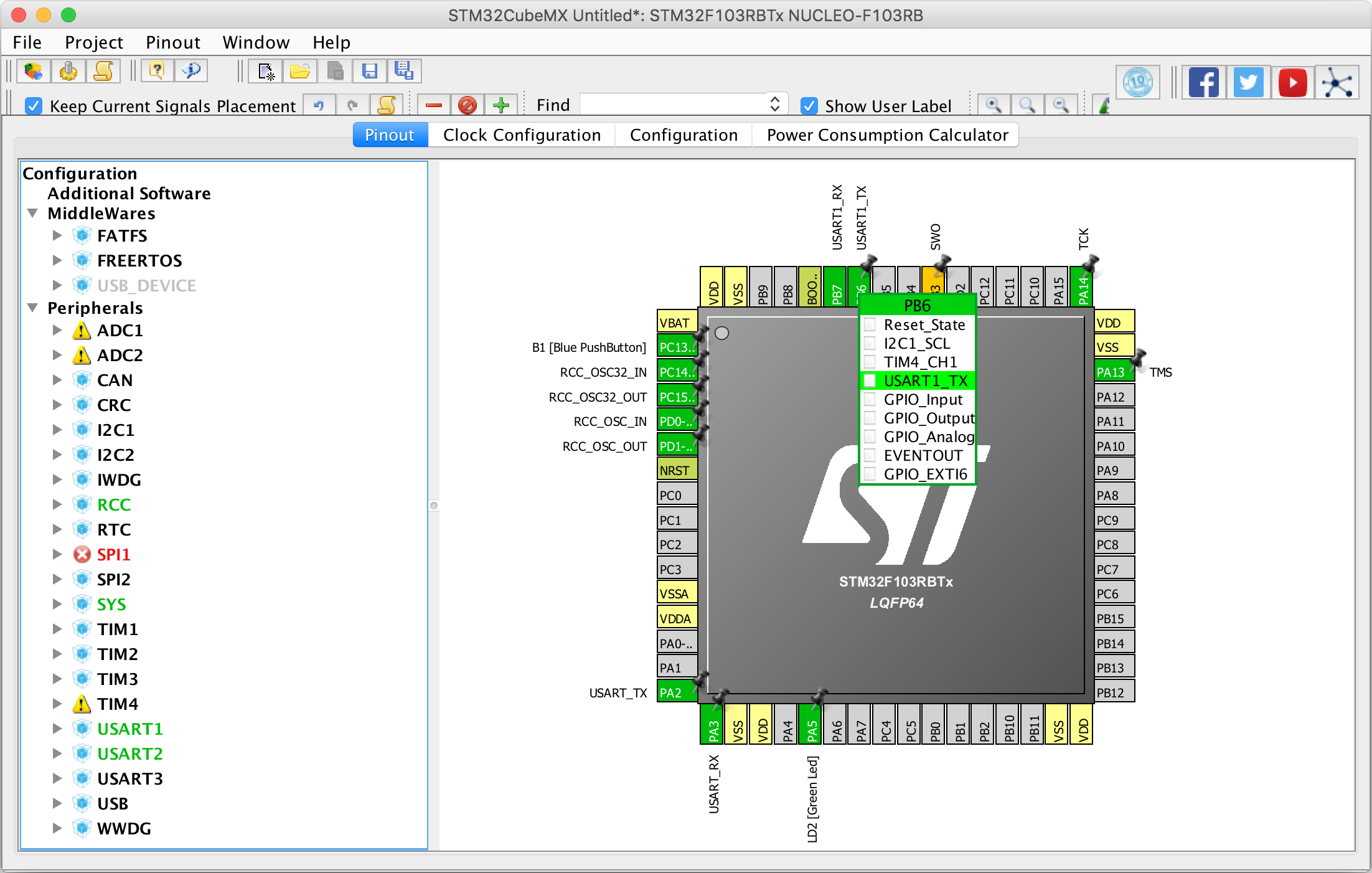
Configuring the USART1_TX signal on pin PB6 on the popular STM32F103RBT.
During installation, CubeMX kindly unpacks a huge plaintext (!) database to disk at STM32CubeMX.app/Contents/Resources/db (on OSX) and even updates it for you on every app launch. This database consists out of a lot of XML files, one for every STM32 device in ST’s portfolio, plus detailed descriptions of peripheral configurations. It really is an insane amount of data.
So I invite you to join me on a stroll through the colorful fields of XML that power the core of the CubeMX’s configurators. I’ll be using the STM32F103RBT, which is a very popular controller that can be found all ST Links and on the Plue Pill board available on ebay for a few bucks.
GPIO Alternate Functions
We start by searching for the unique device identifier STM32F103RBTx in mcu/families.xml (which is >30.000 lines long, btw). The minimal information about the device here is used by the parametric search engine in CubeMX.
<Mcu Name="STM32F103R(8-B)Tx" PackageName="LQFP64" RefName="STM32F103RBTx">
<Core>ARM Cortex-M3</Core>
<Frequency>72</Frequency>
<Ram>20</Ram>
<Flash>128</Flash>
<Voltage Max="3.6" Min="2.0"/>
<Current Lowest="1.7" Run="373.0"/>
<Temperature Max="105.0" Min="-40.0"/>
<Peripheral Type="ADC 12-bit" MaxOccurs="16"/>
<Peripheral Type="CAN" MaxOccurs="1"/>
<Peripheral Type="I2C" MaxOccurs="2"/>
<Peripheral Type="RTC" MaxOccurs="1"/>
<Peripheral Type="SPI" MaxOccurs="2"/>
<Peripheral Type="Timer 16-bit" MaxOccurs="4"/>
<Peripheral Type="USART" MaxOccurs="3"/>
<Peripheral Type="USB Device" MaxOccurs="1"/>
</Mcu>
Following the Mcu/@Name leads us to STM32F103R(8-B)Tx.xml containing what peripherals and how many (mcu/IP/@InstanceName) as well as what pins exists on this package and where and what alternate functions they can be connected to.
<Core>ARM Cortex-M3</Core>
<Ram>20</Ram>
<Flash>64</Flash>
<Flash>128</Flash>
<!-- ... -->
<IP InstanceName="USART3" Name="USART" Version="sci2_v1_1_Cube"/>
<IP InstanceName="RCC" Name="RCC" Version="STM32F102_rcc_v1_0"/>
<IP InstanceName="NVIC" Name="NVIC" Version="STM32F103G"/>
<IP InstanceName="GPIO" Name="GPIO" Version="STM32F103x8_gpio_v1_0"/>
<!-- ... -->
<Pin Name="PB5" Position="57" Type="I/O">
<Signal Name="I2C1_SMBA"/>
<Signal Name="SPI1_MOSI"/>
<Signal Name="TIM3_CH2"/>
</Pin>
<Pin Name="PB6" Position="58" Type="I/O">
<Signal Name="I2C1_SCL"/>
<Signal Name="TIM4_CH1"/>
<Signal Name="USART1_TX"/>
</Pin>
<Pin Name="PB7" Position="59" Type="I/O">
<Signal Name="I2C1_SDA"/>
<Signal Name="TIM4_CH2"/>
<Signal Name="USART1_RX"/>
</Pin>
Each peripheral has a IP/@Version, which leads to a configuration file containing even more data. Don’t cha just love the smell of freshly unpacked data in the morning? For this device’s GPIO peripheral we’ll look for any pins with the USART1_TX signal in the mcu/IP/GPIO-STM32F103x8_gpio_v1_0_Modes.xml file:
<GPIO_Pin PortName="PB" Name="PB6">
<PinSignal Name="USART1_TX">
<RemapBlock Name="USART1_REMAP1">
<SpecificParameter Name="GPIO_AF">
<PossibleValue>__HAL_AFIO_REMAP_USART1_ENABLE</PossibleValue>
</SpecificParameter>
</RemapBlock>
</PinSignal>
</GPIO_Pin>
<!-- ... -->
<GPIO_Pin PortName="PA" Name="PA9">
<PinSignal Name="USART1_TX">
<RemapBlock Name="USART1_REMAP0" DefaultRemap="true"/>
</PinSignal>
</GPIO_Pin>
So USART1_TX maps to pin PB6 with USART1_REMAP1 or pin PA9 with USART1_REMAP0. The STM32F1 series remap signals either in (overlapping) groups or not at all. This is controlled by the AFIO_MAPRx registers, where we can find PB6/PA9 again:

The __HAL_AFIO_REMAP_USART1_ENABLE in the XML is actually just a C function name, and is placed by CubeMX in the generated init code.
void HAL_UART_MspInit(UART_HandleTypeDef* huart)
{
GPIO_InitTypeDef GPIO_InitStruct;
if(huart->Instance==USART1)
{
/* Peripheral clock enable */
__HAL_RCC_USART1_CLK_ENABLE();
/**USART1 GPIO Configuration
PB6 ------> USART1_TX
PB7 ------> USART1_RX
*/
GPIO_InitStruct.Pin = GPIO_PIN_6;
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_HIGH;
HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);
GPIO_InitStruct.Pin = GPIO_PIN_7;
GPIO_InitStruct.Mode = GPIO_MODE_INPUT;
GPIO_InitStruct.Pull = GPIO_NOPULL;
HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);
__HAL_AFIO_REMAP_USART1_ENABLE();
}
}
The IP files do contain a very large amount of information, however, it’s mostly directed at the code generation capabilities of the CubeMX project exporter, and as such, not very useful as stand-alone information. For example, the above GPIO signal information relies on the existence of a __HAL_AFIO_REMAP_USART1_ENABLE() function that performs the remapping. The mapping between the bits in the AFIO_MAPRx registers and the remap groups is therefore encoded in two separate places: these xml files, and the family’s CubeHAL.
The mcu/IP/NVIC-STM32F103G_Modes.xml configuration file, used to configure the NVIC in the CubeMX, exemplifies this quite well: here we see the first 10 interrupt vectors paired with additional metadata (PossibleValue/@Value seems to contain some : separated conditionals for visibility inside the GUI tool).
<RefParameter Comment="Interrupt Table" Name="IRQn" Type="list">
<PossibleValue Comment="Non maskable interrupt" Value="NonMaskableInt_IRQn:N,IF_HAL::HAL_RCC_NMI_IRQHandler:CSSEnabled"/>
<PossibleValue Comment="Hard fault interrupt" Value="HardFault_IRQn:N,W1:::"/>
<PossibleValue Comment="Memory management fault" Value="MemoryManagement_IRQn:Y,W1:::"/>
<PossibleValue Comment="Prefetch fault, memory access fault" Value="BusFault_IRQn:Y,W1:::"/>
<PossibleValue Comment="Undefined instruction or illegal state" Value="UsageFault_IRQn:Y,W1:::"/>
<PossibleValue Comment="System service call via SWI instruction" Value="SVCall_IRQn:Y,RTOS::NONE:"/>
<PossibleValue Comment="Debug monitor" Value="DebugMonitor_IRQn:Y::NONE:"/>
<PossibleValue Comment="Pendable request for system service" Value="PendSV_IRQn:Y,RTOS::NONE:"/>
<PossibleValue Comment="System tick timer" Value="SysTick_IRQn:Y:::"/>
<PossibleValue Comment="Window watchdog interrupt" Value="WWDG_IRQn:Y:WWDG:HAL_WWDG_IRQHandler:"/>
However, their actual position in the interrupt vector table is missing, and so this data cannot be used to extract a valid interrupt table. Instead an alias is used here to pair the interrupt with its actual table position, as defined in the STM32F103xB CMSIS header file.
For example, the WWDG interrupt vector is located at position 16 (=16+0), while the SVCall vector is located at position 11 (=16-5), or 5 positions behind the UsageFault vector:
/*!< Interrupt Number Definition */
typedef enum {
NonMaskableInt_IRQn = -14, /*!< 2 Non Maskable Interrupt */
HardFault_IRQn = -13, /*!< 3 Cortex-M3 Hard Fault Interrupt */
MemoryManagement_IRQn = -12, /*!< 4 Cortex-M3 Memory Management Interrupt */
BusFault_IRQn = -11, /*!< 5 Cortex-M3 Bus Fault Interrupt */
UsageFault_IRQn = -10, /*!< 6 Cortex-M3 Usage Fault Interrupt */
SVCall_IRQn = -5, /*!< 11 Cortex-M3 SV Call Interrupt */
DebugMonitor_IRQn = -4, /*!< 12 Cortex-M3 Debug Monitor Interrupt */
PendSV_IRQn = -2, /*!< 14 Cortex-M3 Pend SV Interrupt */
SysTick_IRQn = -1, /*!< 15 Cortex-M3 System Tick Interrupt */
WWDG_IRQn = 0, /*!< Window WatchDog Interrupt */
// ...
} IRQn_Type;
So keep in mind that this data is not meant to be a sensible hardware description format and it just often lacks basic information that would make it much more useful. Then again, the only consumer of this information is supposed to be CubeMX for its fairly narrow goal of code generation.
Clock Tree
Let’s look at another very interesting data source in CubeMX: the clock configuration wizard:
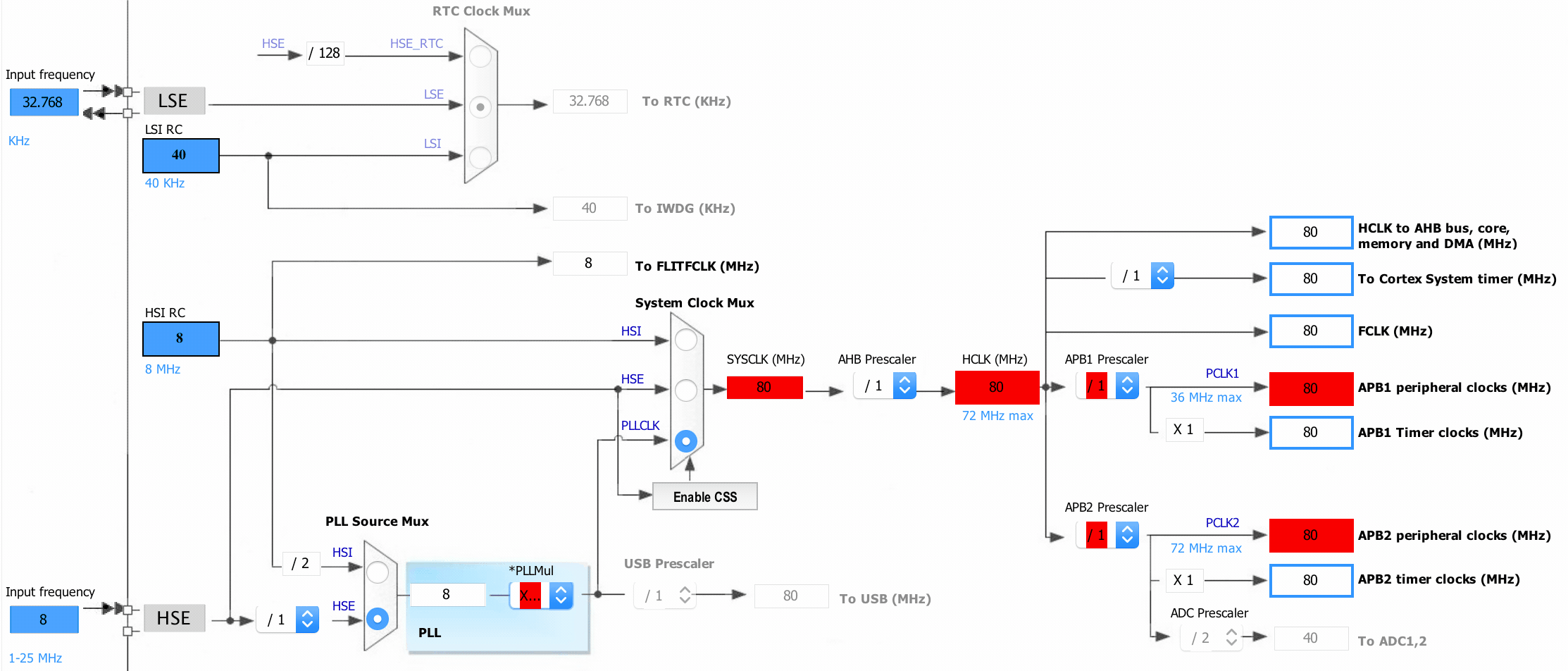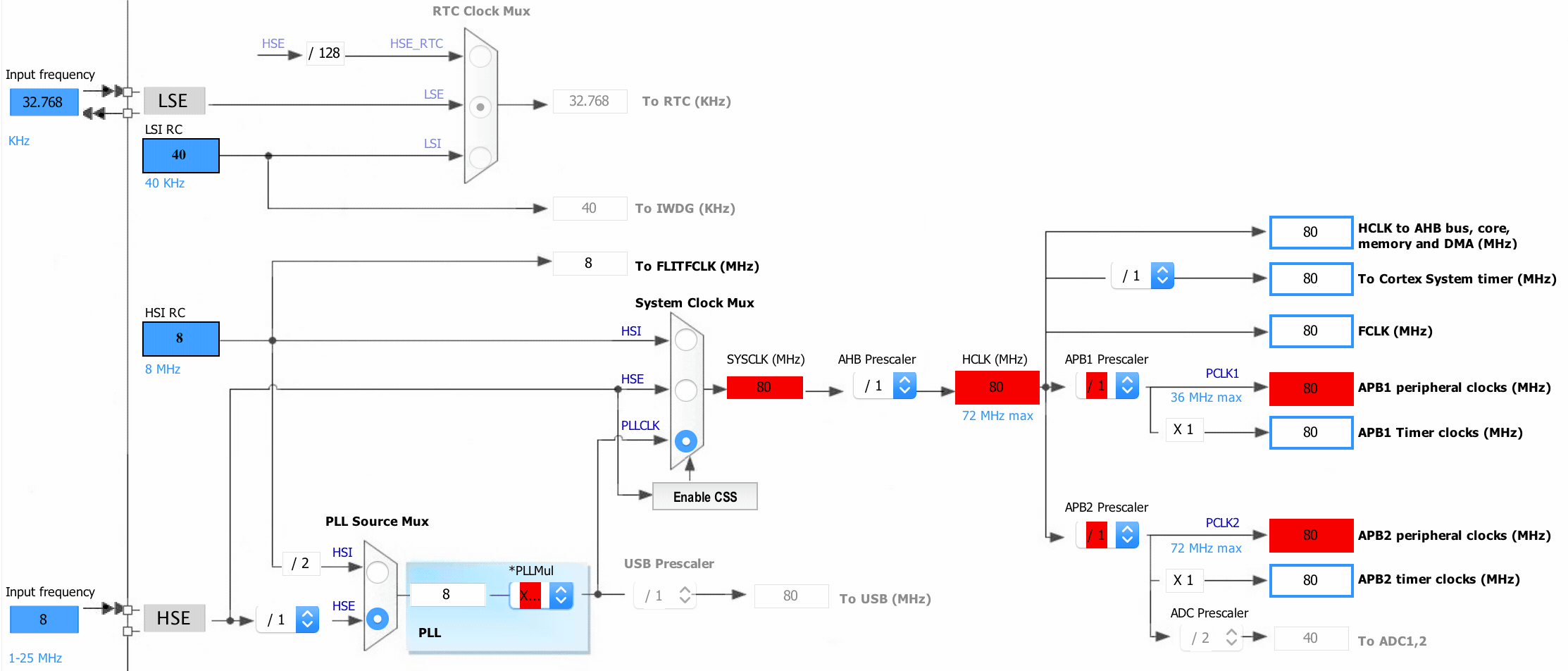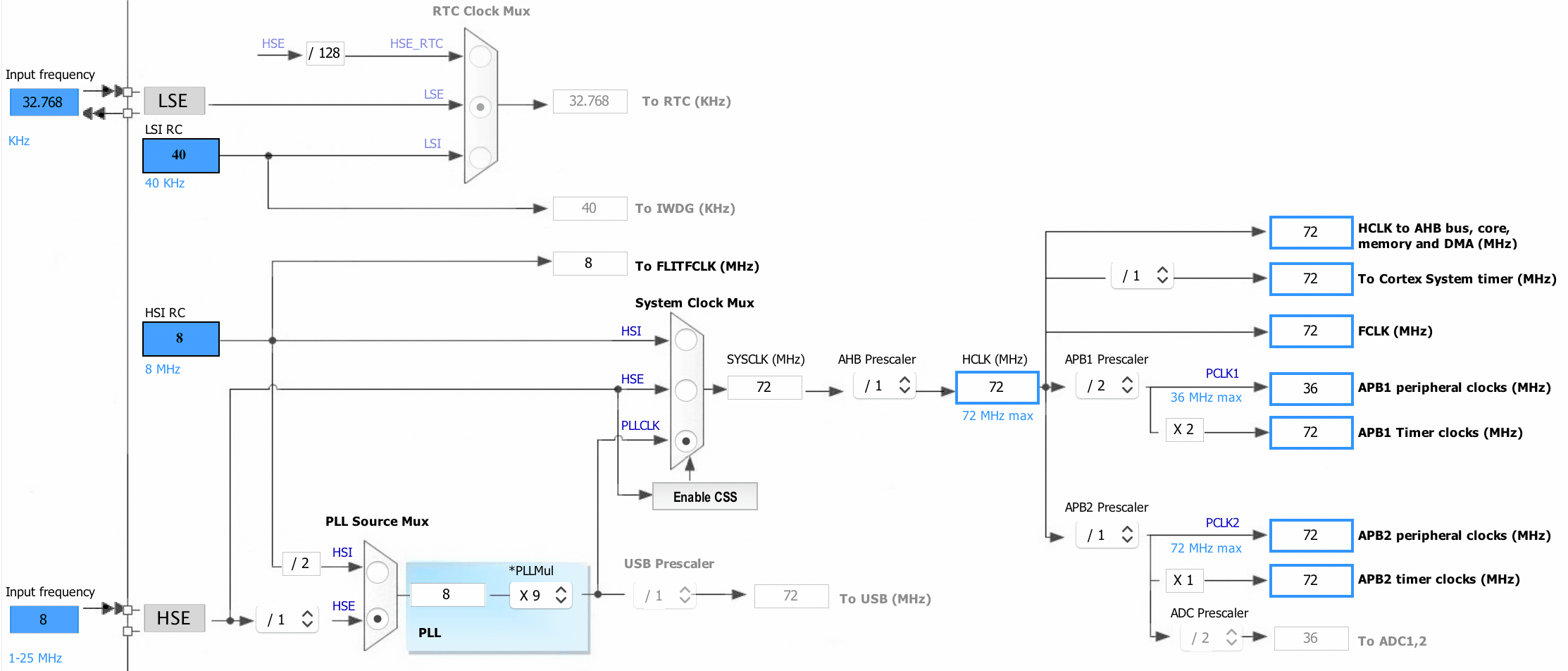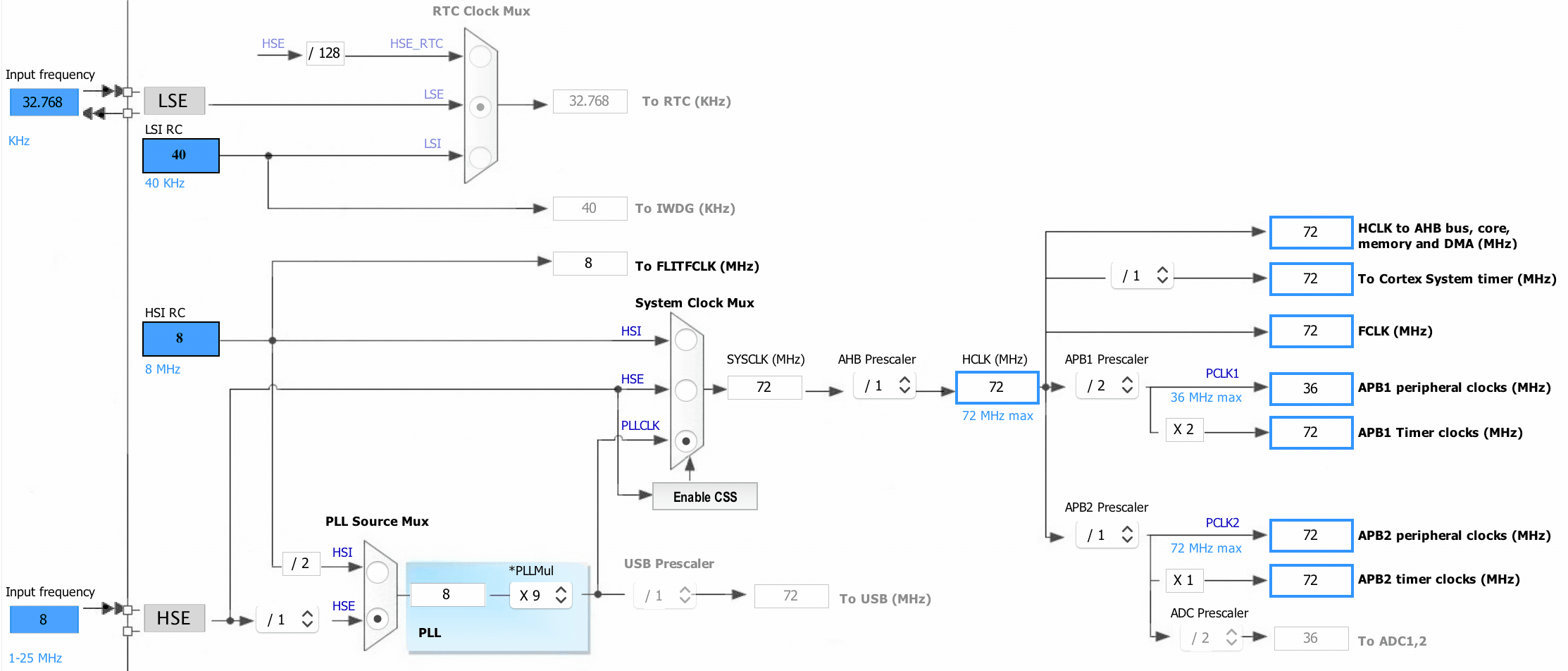
What’s so interesting about this configurator is that it knows what the maximum frequencies of the respective clock segments are, and more importantly, how to set the prescalers to resolve these issues and this for every device. You surely know where this is going by know. Yup, it’s backed by data, and here is what it looks like rendered with graphviz.
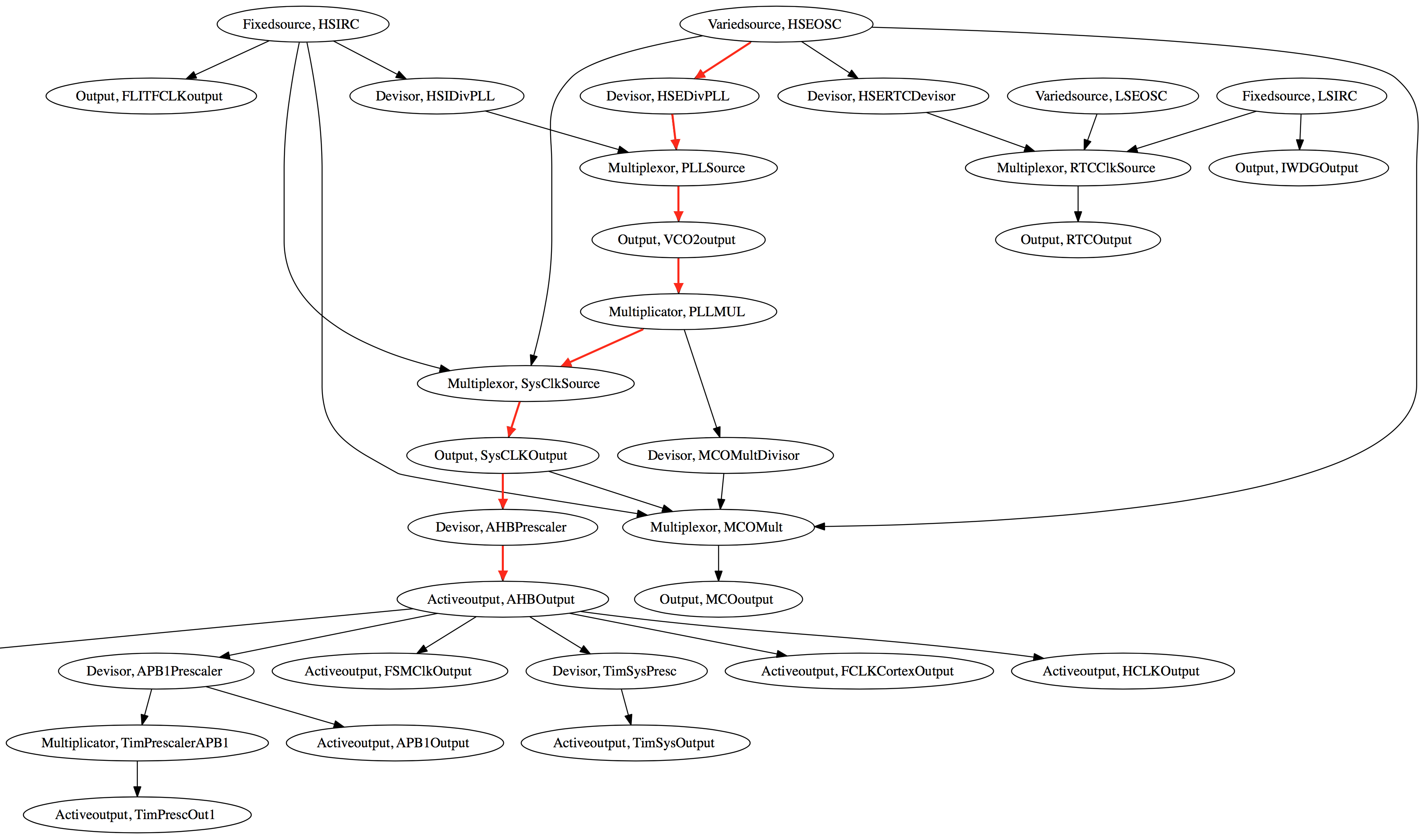
Here is a beautified excerpt from plugins/clock/STM32F102.xml, which only shows the connections highlighted in red. Note how the text in the nodes maps to the Element/@type and Element/@id attributes, and how the Element/Output and Element/Input children declare a (unique) @signalId and which node they are connecting to:
<Tree id="ClockTree">
<!-- HSE -->
<Element id="HSEOSC" type="variedSource" refParameter="HSE_VALUE">
<Output signalId="HSE" to="HSEDivPLL"/>
</Element>
<!-- PLL div input from HSE -->
<Element id="HSEDivPLL" type="devisor" refParameter="HSEDivPLL">
<Input signalId="HSE" from="HSEOSC"/>
<Output signalId="HSE_PLL" to="PLLSource"/>
</Element>
<Tree id="PLL">
<!-- PLLsource MUX source pour PLL mul -->
<Element id="PLLSource" type="multiplexor" refParameter="PLLSourceVirtual">
<Input signalId="HSE_PLL" from="HSEDivPLL" refValue="RCC_PLLSOURCE_HSE"/>
<Output signalId="VCOInput" to="VCO2output"/>
</Element>
<Element id="VCO2output" type="output" refParameter="VCOOutput2Freq_Value">
<Input signalId="VCOInput" from="PLLSource"/>
<Output signalId="VCO2Input" to="PLLMUL"/>
</Element>
<Element id="PLLMUL" type="multiplicator" refParameter="PLLMUL">
<Input signalId="VCO2Input" from="VCO2output"/>
<Output signalId="PLLCLK" to="SysClkSource"/>
</Element>
</Tree>
<!--Sysclock mux -->
<Element id="SysClkSource" type="multiplexor" refParameter="SYSCLKSource">
<Input signalId="PLLCLK" from="PLLMUL" refValue="RCC_SYSCLKSOURCE_PLLCLK"/>
<Output signalId="SYSCLK" to="SysCLKOutput"/>
</Element>
<Element id="SysCLKOutput" type="output" refParameter="SYSCLKFreq_VALUE">
<Input signalId="SYSCLK" from="SysClkSource"/>
<Output signalId="SYSCLKOUT" to="AHBPrescaler"/>
</Element>
<!-- AHB input**SYSclock** -->
<Element id="AHBPrescaler" type="devisor" refParameter="AHBCLKDivider">
<Input signalId="SYSCLKOUT" from="SysCLKOutput"/>
<Output signalId="HCLK" to="AHBOutput"/>
</Element>
<!-- AHB input**SYSclock** output**FHCLK,HCLK,Diviseurcortex,APB1,APB2 -->
<Element id="AHBOutput" type="activeOutput" refParameter="HCLKFreq_Value">
<Input signalId="HCLK" from="AHBPrescaler"/>
<Output to="FCLKCortexOutput" signalId="AHBCLK"/>
<Output to="FSMClkOutput" signalId="AHBCLK"/>
<Output to="SDIOClkOutput" signalId="AHBCLK"/>
<Output to="HCLKDiv2" signalId="AHBCLK"/>
<Output to="HCLKOutput" signalId="AHBCLK"/>
<Output to="TimSysPresc" signalId="AHBCLK"/>
<Output to="APB1Prescaler" signalId="AHBCLK"/>
<Output to="APB2Prescaler" signalId="AHBCLK"/>
</Element>
</Tree>
We still don’t know how CubeMX is able to do it actual calculations, because the clock graph above doesn’t contain any numbers at all. Some digging around later we can trace the Element/@refParameter attribute to the IP/RCC-STM32F102_rcc_v1_0_Modes.xml which contains *drumroll* numbers, and lots of ‘em:
<!-- Les frequences des sources -->
<RefParameter Name="HSE_VALUE" Min="4000000" Max="16000000" Display="value/1000000" Unit="MHz"/>
<!-- frequence PLL -->
<RefParameter Name="VCOOutput2Freq_Value" Min="1000000" Max="25000000" Display="value/1000000" Unit="MHz"/>
<!-- les diviseurs -->
<RefParameter Name="HSEDivPLL" DefaultValue="RCC_HSE_PREDIV_DIV1">
<PossibleValue Comment="1" Value="RCC_HSE_PREDIV_DIV1"/>
<PossibleValue Comment="2" Value="RCC_HSE_PREDIV_DIV2"/>
</RefParameter>
<!-- Les multiplicateurs -->
<RefParameter Name="PLLMUL" DefaultValue="RCC_PLL_MUL2">
<PossibleValue Comment="2" Value="RCC_PLL_MUL2"/>
<!-- ... -->
<PossibleValue Comment="16" Value="RCC_PLL_MUL16"/>
</RefParameter>
<!-- Les frequences des signaux -->
<!-- SYS clock freq de l'output -->
<RefParameter Name="SYSCLKFreq_VALUE" Max="72000000" Display="value/1000000" Unit="MHz"/>
<!-- diviseur AHB 1..512 -->
<RefParameter Name="AHBCLKDivider" DefaultValue="RCC_SYSCLK_DIV1">
<PossibleValue Comment="1" Value="RCC_SYSCLK_DIV1"/>
<PossibleValue Comment="2" Value="RCC_SYSCLK_DIV2"/>
<PossibleValue Comment="4" Value="RCC_SYSCLK_DIV4"/>
<PossibleValue Comment="8" Value="RCC_SYSCLK_DIV8"/>
<PossibleValue Comment="16" Value="RCC_SYSCLK_DIV16"/>
<PossibleValue Comment="64" Value="RCC_SYSCLK_DIV64"/>
<PossibleValue Comment="128" Value="RCC_SYSCLK_DIV128"/>
<PossibleValue Comment="256" Value="RCC_SYSCLK_DIV256"/>
<PossibleValue Comment="512" Value="RCC_SYSCLK_DIV512"/>
</RefParameter>
<!-- AHB out freq -->
<RefParameter Name="HCLKFreq_Value" Max="72000000" Display="value/1000000" Unit="MHz"/>
Did you know that ST is a French-Italian company? Cos those XML comments clearly aren’t in English. 🤔 Well, that and they seem keen on calling it a “devisor” when they really mean “divider”. What is this, I don’t even.

French comments in XML
Anyways, here you can see the RefParameter/@min and RefParameter/@max frequency values as well as prescaler values encoded as PossibleValue/@Comment, which are all used by CubeMX to check and fix your clock tree. That’s pretty amazing actually.
Ok, so I’m not going into the data of their board support packages, because I don’t think any health insurance covers this much exposure to XML, especially not XML containing French comments. But feel free to take a look at your own risk, it’s just waiting there in plugins/boardmanager/boards for your prying eyes.
Let’s move on to how we can extract this data programmatically and use it to bring order to chaos, one example at a time. A bit like the Avengers franchise *drags out blog post to infinity*
Generating Device Files
The goal of finding machine-readable device description data obviously was to write a program to import, clean-up and convert it into a format that’s more agreeable to our use-case of generating a HAL. Ironically the Device File Generator (DFG) started out in mid 2013 with the innocently named commit “Cheap and simple parsing of the XML files”. It’s not cheap and simple anymore.
The DFG started out as a glorified XPath wrapper in xpcc, but then quickly devolved into some messy monster, that pulled in data from all over the place and arranged it without much concept. Back then we were busy building porting the HAL, writing sensor drivers and building robots, so we didn’t approach this problem structurally, and rather fixed bugs when they occurred.
I won’t talk about xpcc’s DFG architecture issues in detail, instead I’ll be showing you the problems it caused us. This way, the lessons learned are more transferable to other format (*cough* Device Tree *cough*), since the device data is immutable whereas the DFG’s architecture is not.
Note that I rewrote the DFG from scratch for modm, so you can have a look at the source code while reading this. I’m continuing to use the STM32F103RBT6 for illustration, but this all works very similarly for all STM32 and AVR devices.
Device Identifiers
We needed a way to identify what device to build our HAL for, and of course we use the manufacturers identifier, since it’s (hopefully) unique. We also needed to split up the identifier string, so that the HAL can query its traits to select what code templates to use. For example, in xpcc we split stm32f103rbt6 into:
stm32 f1 103 r b
{platform}{family}{name}{pin-id}{size-id}
Note how we forgot the t6 suffix. If we compare this with the documentation on the ST ordering information scheme, you’ll see why this was a huge mistake:
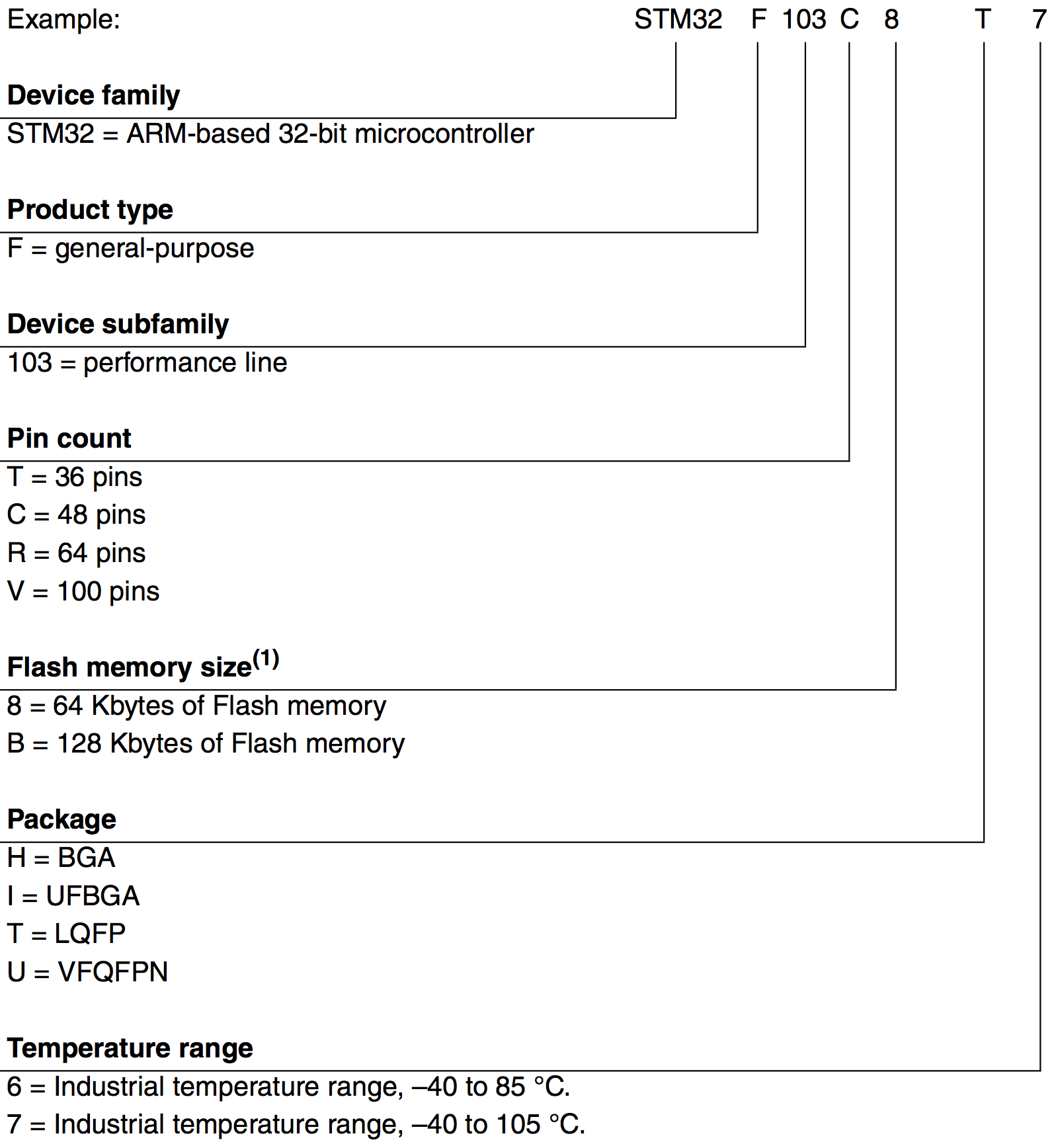
Yup, that’s right, we forgot to encode the package type, causing the DFG to select the first device matching STM32F103RB! And that would be the STM32F103RBHx device, since it occurs first in families.xml.
<Mcu Name="STM32F103R(8-B)Hx" PackageName="TFBGA64" RefName="STM32F103RBHx">
<!-- ... -->
<Mcu Name="STM32F103R(8-B)Tx" PackageName="LQFP64" RefName="STM32F103RBTx">
So we actually used the definitions for the TFBGA64 packaged device instead of the LQFP64 packaged device. 🤦 Incredibly this didn’t cause immediate problems, since we first focussed on the STM32F3 and F4 families, whose functionality is almost identical between packages.
However, we did notice some changes when a new version of CubeMX was released which added or reordered devices in families.xml. And then all hell broke loose when I added support for parsing the STM32F1 device family, which couples peripheral features to memory size and(!) pin count:
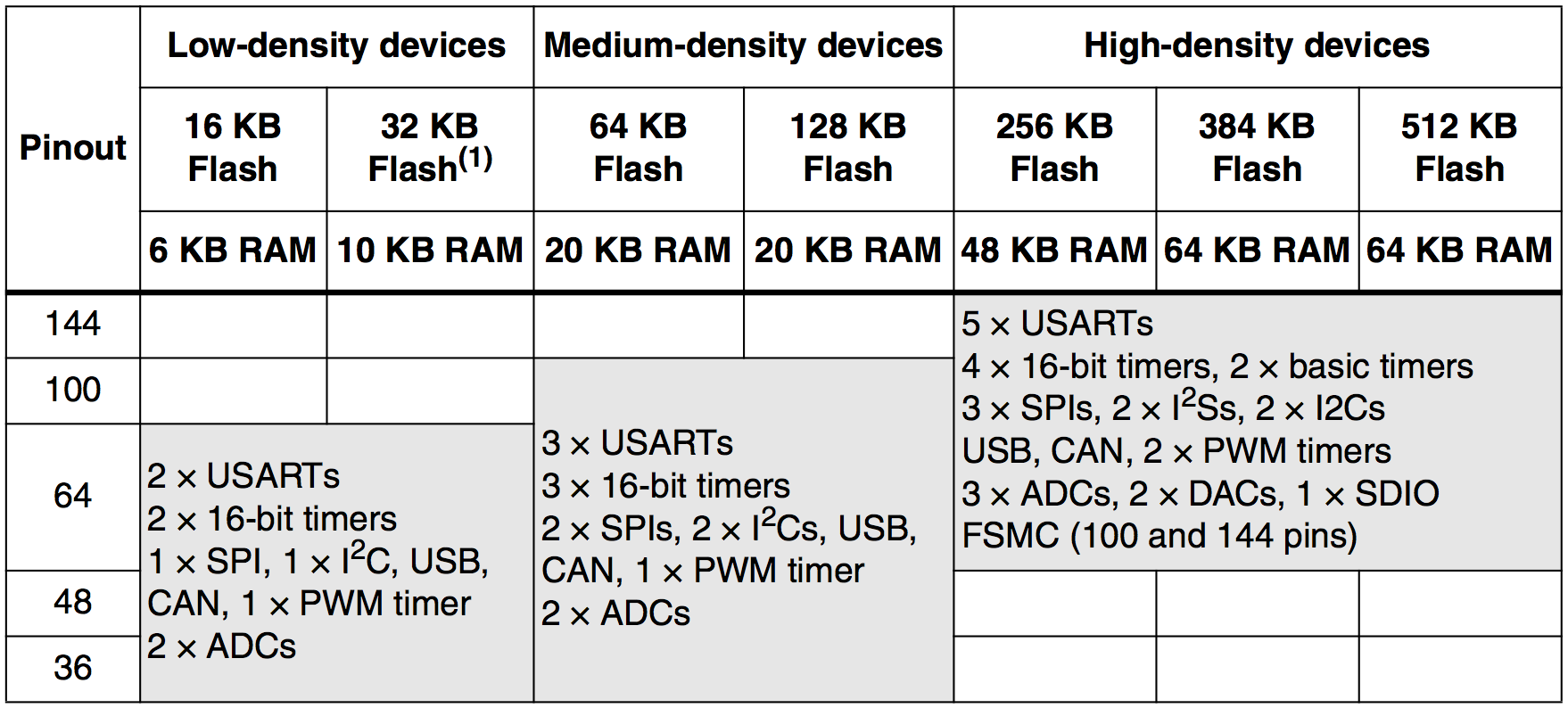
“32 KB Flash(1)” aka. this table isn’t complicated enough already
If you’re a hardware engineer at $vendor, PLEASE DON’T DO THIS! This is pure punishment for anyone writing software for these chips. PLEASE DO NOT DO THIS! You should not have to query for combinations of identifier traits to get your hardware feature set. Expand your device lineup into new (orthogonal) identifier space instead.

To be fair, the STM32F1 family was the first ST product to feature a Cortex-M processor and they didn’t use this approach for any of their other STM32 families. I forgive you, ST.
So for modm I looked very carefully at how to split the identifier into traits. I made the trait composition and naming transparent to the DFG, it only operates on a dictionary of items, sharing the same identifier mechanism with the AVRs. Since we currently don’t have any information that depends on the temperature range, I left it out for now. Similarly, the device revision is not considered either.
stm32 f1 03 r b t
{platform}{family}{name}{pin}{size}{package}
Note how both the xpcc and modm identifier encodings differ from the official ST ordering scheme. Since we are sharing some code across vendors (like the Cortex-M startup code), we need to have a common naming scheme, at least for {platform} and {family} or the equivalent for other vendors.
Also note that {name} now does not contain part the trailing 1 of the family. This is to prevent the problem in xpcc where the code template authors only checked for the {name} instead of the {family} and {name}, for example, id["name"] == "103" vs. id["family"] == "f1" and id["name"] == "03". This lead to issues when we ported some peripheral drivers to the L1 family (similar to F0/L0, F4/L4 and F7/H7).
Encoding Commonality
You’ve undoubtedly already noticed that the AVR and CubeMX data is quite verbose and noisy. We didn’t want to use this data directly, hence the DFG. However, we wanted to go a step further and cut down on duplicated data, so that we have an easier time verifying the output of the DFG by not having to look through thousands of files, but rather dozens.
At the time of this writing, families.xml contains 1171 STM32 devices, but modm-devices/devices/stm32 only contains 62 device files, that’s ~19x less files than devices.
We observed that ST clusters their devices on their website, in their technical documentation and in their software offerings. The coarsest regular cluster pattern is the family, which denotes the type of Cortex-M code used among other features. The subfamilies are then more or less arbitrarily clustered around whatever combination of functionality ST wanted to bring to market, but the cluster patterns of pin count, memory size and package are very regular and often explicitly called out. We wanted to reflect this in our data structure too.
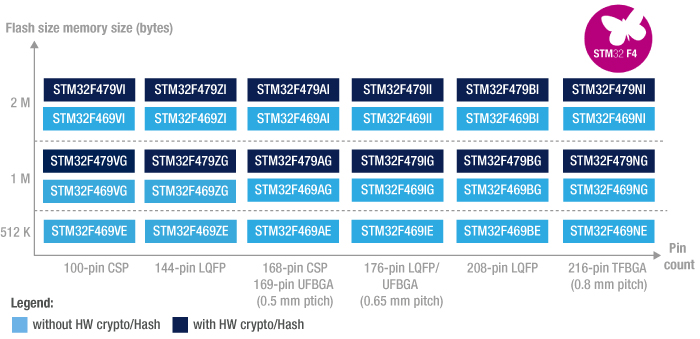
This STM32F4x9 feature matrix is extremely regular.
The Device Tree format deals with data duplication by allowing data specialization through an inheritance tree and tree inclusion nodes. However, you still have to create one leaf node for every device, so in the best case you’d have one DT per device, or if you moved common data up the inheritance tree, you’d have more files than devices.
We decided instead to merge our data trees for devices within similar enough clusters and then filter out the data for one device on access. We use logical OR (|) to combine identifier traits to declare what devices are merged. You’ll recognize the <naming-schema> from the previous chapter:
<device platform="stm32" family="f1" name="03" pin="c|r|t|v" size="8|b" package="h|i|t|u">
<naming-schema>{platform}{family}{name}{pin}{size}{package}</naming-schema>
<valid-device>stm32f103c8t</valid-device>
<!-- ... -->
<valid-device>stm32f103rbt</valid-device>
This device file for the F103x8/b devices therefore contains all that match the identifier pattern of r"stm32f103[crtv][8b][hitu]". The engine extracting the data set for a single device will first construct a list of all possible identifier strings via the naming schema and the device combinations: 4*2*4 = 32 identifiers in this example. It then filters these identifiers by the list in <valid-device>, since not every combination actually exists. Whatever device file contains the requested identifier string is then used.
The identifier schema does not have to include all traits either, it only has to be unambiguous. For example the AVR device identifier schema does not contain {platform} but we can infer it anyways:
<device platform="avr" family="mega" name="48|88|168|328" type="|a|p|pa">
<naming-schema>at{family}{name}{type}</naming-schema>
It first seems unnecessary to do this reverse lookup, but it gives us a very important property for free: The extractor does not need to know anything about the identifier, and still understands the mapping of string to traits. So passing stm32f103rbt is now understood as stm32 f1 03 r b t. The disadvantage is having to first build all identifier strings, before returning the corresponding device file. However, this mapping can be cached.
The device file can now use the traits as filters by prefixing them with device-. For our example, the device file continues with declaring the core driver instance, which contains the memory map and vector table. The devices here only differ in Flash size, otherwise they are identical:
<driver name="core" type="cortex-m3">
<memory device-size="8" name="flash" access="rx" start="0x8000000" size="65536"/>
<memory device-size="b" name="flash" access="rx" start="0x8000000" size="131072"/>
<memory name="sram1" access="rwx" start="0x20000000" size="20480"/>
<vector position="0" name="WWDG"/>
<vector position="1" name="PVD"/>
<!-- ... -->
<vector position="42" name="USBWakeUp"/>
By applying some simple combinatorics math we can find the minimal trait set that uniquely describes this difference and can push this filter as far up the data tree as possible while still being unambiguous and therefore losslessly reconstructible for all merged device data. This is all done for the sole purpose of optimizing for human readability, so an embedded engineer with some experience can just look at this data and say: “This filter looks too noisy to me, so something is probably is wrong here” 🤓 *sound of datasheet pages flipping*.
Here is an example of what I so dramatically complained about before: The STM32F1 peripheral feature set is coupled to the device’s pin count: F103 devices with just 36 pins have fewer instances of these peripherals:
<driver name="i2c" type="stm32">
<instance value="1"/>
<instance device-pin="c|r|v" value="2"/>
</driver>
<driver name="spi" type="stm32">
<instance value="1"/>
<instance device-pin="c|r|v" value="2"/>
</driver>
<driver name="usart" type="stm32">
<instance value="1"/>
<instance value="2"/>
<instance device-pin="c|r|v" value="3"/>
</driver>
Of course both the pin count and the package influence the number of available GPIOs and signals. The algorithm here detected that using the pin count as a filter is enough to safely reconstruct the tree, so the device-package is missing (it prioritizes traits further “left” in the identifier):
<driver name="gpio" type="stm32-f1">
<!-- ... -->
<gpio device-pin="r|v" port="c" pin="10"/>
<gpio device-pin="r|v" port="c" pin="11">
<signal driver="adc" instance="1" name="exti11"/>
<signal driver="adc" instance="2" name="exti11"/>
</gpio>
<gpio device-pin="r|v" port="c" pin="12"/>
<gpio device-pin="c|r|v" port="c" pin="13">
<signal driver="rtc" name="out"/>
<signal driver="rtc" name="tamper"/>
</gpio>
The device- filter traits are ORed, multiple filters on the same node ANDed, and the nodes themselves ORed together again. Keen observers will point out that this can create overly broad filters which would make for incorrect reconstruction. For these cases we have to create two nodes with the same data, but different filters to avoid ambiguity. Here is an example from the STM32F4{27,29,37,39} device file:
<gpio port="c" pin="3">
<!-- ... -->
<signal device-name="27|37" device-pin="a|i|v|z" af="12" driver="fmc" name="sdcke0"/>
<signal device-name="29|39" device-pin="a|b|i|n|z" af="12" driver="fmc" name="sdcke0"/>
</gpio>
Hm, but that filter does look suspiciously noisy, doesn’t it? This filter pattern is repeated for the sdne[1:0] and sdnwe signals, which all belong to the SDRAM controller in the FMC. And according to this data set they seem to be unavailable for the LQFP100 package? Hm, better call Saul check the datasheets:
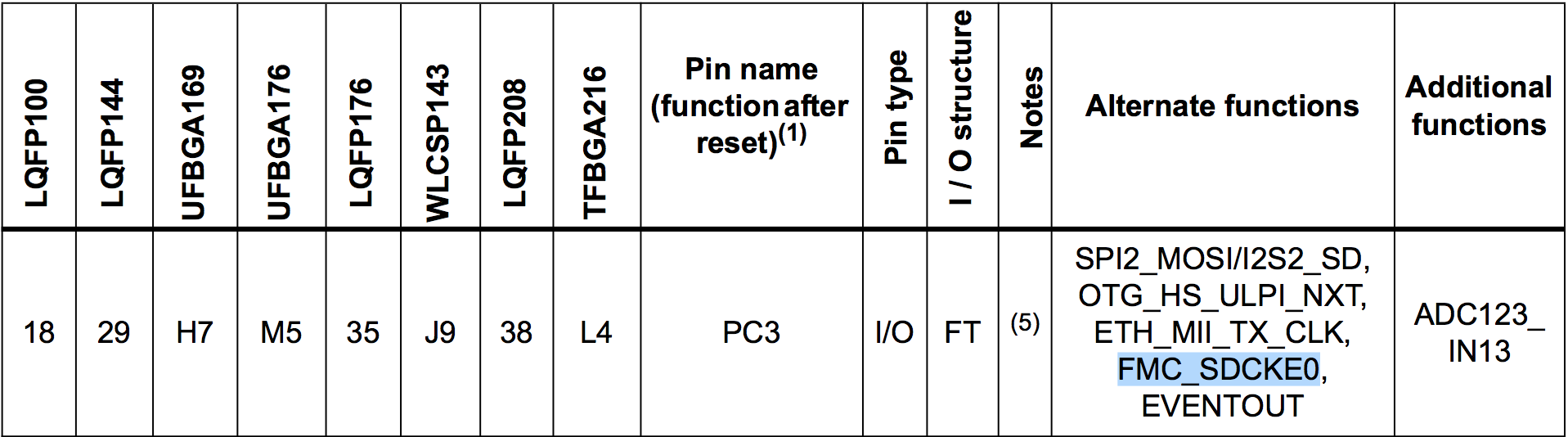

Huh, but the signals do exist for the LQFP100 package!?

“FMC: Yes(1)”. Oh, FFS!
I checked with CubeMX and the GPIO configurator doesn’t allow you to set SDRAM signals in the LQFP100 package, and there are no STM32F4[23]7[BN] devices, so everything is fine, I guess? Nothing to see here folks, move along, the filter algorithm encoded this shit correctly. 🙃

Anyways, I like our device file format a lot, since it describes the device’s hardware in such a compact and concise form. However, it doesn’t scale graciously at all for data that shares less commonalities between devices in the current clusters.
Data Pipeline
For my rewrite of the DFG for modm I wanted to improve the correctness of device merges, remove device specific knowledge as much as possible, support multiple output formats and rename less data. I’ve already hinted at solutions to some of these in the previous chapters, so let’s have a proper look at them now.
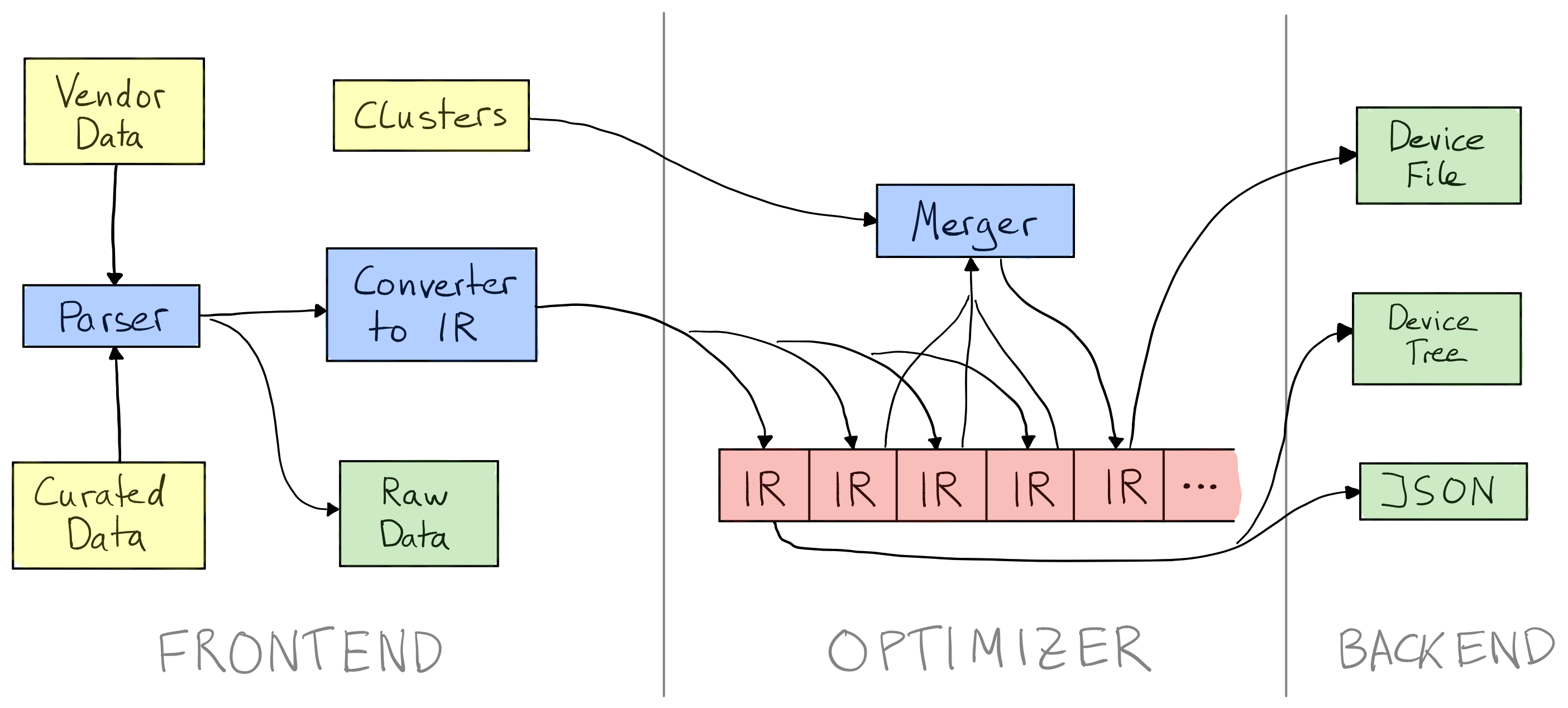
The DFG has three parts: frontend, optimizer and backend. Here yellow stands for input data, blue for data conversion, red for intermediate representation (IR) and green for output data. I’ve already covered the vendor input data and the device merging in much detail.
All the ugly is in the parser, it reads the CubeMX data in the same manner I’ve described previously, performs plausibility and format checks on it, and finally normalizes it into a simple Python dictionary. This is just mostly mind-numbingly stupid code to write, since you have to XPath query the CubeMX sources, deal with all the edge cases in the results and normalize all data relative to all devices. Ugly to write, ugly to read, but it gets the job done.
Additional curated data gets injected in this step too. The CubeMX data contains a hardware IP version, which seems to correlate loosely to the peripherals feature set, however, I didn’t find it very useful to distinguish between them. So instead I looked up how all peripherals work in the documentation and grouped them again manually. The device file driver/@type name comes from this data.
For example, here we can see that the entire STM32 platform only has three different I2C hardware implementations, one of which only differs with the addition of a digital noise filter.
'i2c': [{
'instances': '*',
'groups': [
{
# This hardware can go up to 1MHz (Fast Mode Plus)
'hardware': 'stm32-extended',
'features': [],
'devices': [{'family': ['f0', 'f3', 'f7']}]
},{
'hardware': 'stm32l4',
'features': ['dnf'],
'devices': [{'family': ['l4']}]
},{
# Some F4 have a digital noise filter
'hardware': 'stm32',
'features': ['dnf'],
'devices': [{'family': ['f4'], 'name': ['27', '29', '37', '39', '46', '69', '79']}]
},{
'hardware': 'stm32',
'features': [],
'devices': '*'
}
]
}]
All names of peripherals, instances, signals are preserved as they are, so that the name matches the documentation. The only exception are names that wouldn’t be valid identifiers in most programming languages. For our STM32F103RBT example, we split up and duplicate these system signals:
SYS_JTCK-SWCLK => sys.jtck + sys.swclk
SYS_JTDO-TRACESWO => sys.jtdo + sys.traceswo
SYS_JTMS-SWDIO => sys.jtms + sys.swdio
The dictionary returned by the parser is then passed onto a platform specific converter that transforms it into the DFGs intermediate representation. Here the raw data is formatted into a glorified tree structure, which has similar semantics to a very restricted form of XML (ie. attributes are stored separately from its children) and annotates each node with the device’s identifier.
Here the memory maps and the interrupt vector table is added to the name="core" driver node we saw before. The raw data already contains the memories and vectors with the right naming scheme, so it’s easy to just add them here.
for section in p["memories"]:
memory_node = core_driver.addChild("memory")
memory_node.setAttributes(["name", "access", "start", "size"], section)
for vector in p["interrupts"]:
vector_node = core_driver.addChild("vector")
vector_node.setAttributes(["position", "name"], vector)
# sort the node children by start address and size
core_driver.addSortKey(lambda e: (int(e["start"], 16), int(e["size"]))
if e.name == "memory" else (-1, -1))
# sort the node children by vector number and name
core_driver.addSortKey(lambda e: (int(e["position"]), e["name"])
if e.name == "vector" else (-1, ""))
I’m adding two sort keys to the core driver node here, to bring the entire tree into canonical order. This an absolute requirement for the reproducibility of the results, otherwise I wouldn’t be able to tell what data changed if the line order came out differently on each invocation.
It’s time to merge the device IRs now. The device clustering is curated manually, by a large list of identifier trait groups. I considered using some kind of heuristic to automate this, but this works really well, particularly for the AVR and STM32F1 devices. It’s difficult to come up with a metric that accurately describes how annoyed I feel when looking at wrongfully merged device files with lotsa noisy filters. 😤
The STM32F103 devices are split into these four groups:
{
'family': ['f1'],
'name': ['03'],
'size': ['4', '6']
},{
'family': ['f1'],
'name': ['03'],
'size': ['8', 'b']
},{
'family': ['f1'],
'name': ['03'],
'size': ['c', 'd', 'e']
},{
'family': ['f1'],
'name': ['03'],
'size': ['f', 'g']
}
In case you’re curious how bad it would be with just one large F103 group, here is a gist with the resulting device file. It’s not as bad as it could be, but still much harder to read.
At this point the merged IR for our F103RBT device basically already looks like the finished device file, including identifier filters:
device <> stm32f103[c|r|t|v][8|b][h|i|t|u]
. driver <name:core type:cortex-m3>
. memory <name:flash access:rx start:0x8000000 size:65536> stm32f103[c|r|t|v]8[h|t|u]
. memory <name:flash access:rx start:0x8000000 size:131072> stm32f103[c|r|t|v]b[h|i|t|u]
. memory <name:sram1 access:rwx start:0x20000000 size:20480>
. vector <position:0 name:WWDG>
...
. vector <position:42 name:USBWakeUp>
. driver <name:i2c type:stm32>
. instance <value:1>
. instance <value:2> stm32f103[c|r|v][8|b][h|i|t|u]
. driver <name:spi type:stm32>
. instance <value:1>
. instance <value:2> stm32f103[c|r|v][8|b][h|i|t|u]
I’ve already described the device file format above, however, one additional testing step is done before the DFG is finished: A copy of every single device file is taken before merging, so that it can be compared with the device files that are extracted from this merged one. This is a brute-force test to make sure the filter algorithms did perform correctly.
On a side note, the conversion from IR to device file format can be performed at any time, so that last merge step is strictly speaking optional. This is useful for debugging but also if you want to output this data in a format that does not support a merge mechanism similar to the device file’s one, like plain JSON.
Using Device Files
So now that we have all this data, let’s have some fun with it. modm-devices comes not only with the DFG but also with a device file parser, which can be used like this:
>>> import modm.parser, glob
>>> devices = {}
>>> for filename in glob.glob("path/to/modm-devices/devices/**/*.xml"):
>>> for device in modm.parser.DeviceParser().parse(filename).get_devices():
>>> devices[device.partname] = device
>>> devices["stm32f103rbt"].properties
{'driver': [{'memory': [{'access': 'rx',
'name': 'flash',
'size': '131072',
'start': '0x8000000'},
{'access': 'rwx',
'name': 'sram1',
'size': '20480',
'start': '0x20000000'}],
'name': 'core',
'type': 'cortex-m3',
... }]
}
There are some built-in convenience functions for accessing some of the common data in the device files:
>>> device = devices["stm32f103rbt"]
>>> device.identifier
OrderedDict([('platform', 'stm32'), ('family', 'f1'), ('name', '03'), ('pin', 'r'), ('size', 'b'), ('package', 't')])
>>> device.has_driver("usart:avr")
False
>>> device.has_driver("usart:stm32")
True
>>> device.get_driver("usart:stm32")
{'instance': ['1', '2', '3'], 'name': 'usart', 'type': 'stm32'}
I’ve also written a short stats script that allows you to compute some very basic information about the device file collection:
$ python3 tools/device/scripts/stats --count
1355 devices
$ python3 tools/device/scripts/stats --driver
{
"ac": 234,
"adc": 1339,
"aes": 133,
"awex": 26,
"bandgap": 8,
"battery_protection": 7,
"bdma": 20,
"bod": 30,
"can": 683,
"ccl": 30,
"cell_balancing": 5,
"cfd": 2,
"charger_detect": 4,
"clk": 45,
"clock": 242,
"comp": 577,
"core": 1355,
...
}
stats also allows you to dump expanded JSON for a prefix of devices and then query that with the tool of your choice to, for example, get all the I2C related signals on port B for the STM32F4 device family. Not sure why you’d want that, but it’s possible.
$ python3 tools/device/scripts/stats --json stm32f4 | jq '[.[] | .device.driver[] | select(.name == "gpio").gpio[] | . as $gpio | .signal[]? | select(.driver == "i2c" and $gpio.port == "b") | ($gpio.port + $gpio.pin + ":" + .name)] | unique'
[
"b10:scl",
"b11:sda",
"b12:smba",
"b3:sda",
"b4:sda",
"b5:smba",
"b6:scl",
"b7:sda",
"b8:scl",
"b8:sda",
"b9:sda"
]
I’ll discuss in more detail how we use the device files in the next blog post about the modm library.
Try it Yourself
The device file as well as the DFG are available on GitHub for you to play with. It automatically downloads and extracts all the raw data into modm-devices/tools/generator/raw-device-data folder.
git clone --recursive --depth=1 https://github.com/modm-io/modm-devices.git
cd modm-devices/tools/generator
# Extract and generate STM32 device data
make extract-data-stm32
make generate-stm32
# Extract and generate AVR device data
make extract-data-avr
make generate-avr
Not everything I described here is fully implemented, for example, the clock graph extractor is just a proof-of-concept for now. modm-devices is also supposed to be a Python package installable via pip, but that’s not implemented yet.
Please help me maintain this project, I only used devices from a few STM32 families, so it’s difficult to judge the correctness of some of this data. If you know of any other machine readable data, please open an issue or preferrably a pull request.
Two more device file checks are currently not implemented: a XML schema validation, and a semantical checker, that verifies the contents consistency. For example, every GPIO signal should be associable with a driver, and no signal name should start with a number (otherwise difficult to map into most programming languages). These are ideas for the future.
With some effort and additional data sources (CMSIS-SVD files for example), directly outputting to Device Tree format should be possible too. I leave that one to the experts though. 😇
Conclusion
It was important to use not to bind this data to any preconceptions of its use by, for example, integrating it tightly into our HAL generator. Instead we’ve very carefully separated modm-devices from our use of it, so that it can stand on its own and be integrated into all sorts of projects by the community. You’re not bound to using this in code either, you can also generate Markdown documentation, or maybe build your own GPIO configurator as a web UI.
You can go and use it as is with its Python DeviceFile interface, however, for larger projects, I’d recommend you write your own wrapper class, that can format the data as you need it. The Device File format may change at any time, so that I can fit in new data or once I don’t like the format anymore, change it completely. So don’t depend on the format directly.
The next few blog posts will be about applying this data in our own modm library, how CMSIS-SVD compares to CMSIS Headers as additional data sources, and what it means to model check your HAL with this data.
On a Personal Note
The last 5 years working on this have been quite a ride. It has completely changed my view on embedded software engineering and it took a while for me understand this different way of thinking. As far as I know, nobody has deployed hardware description methods on such a large and diverse device base. And we’re just getting started.
I’ve been fortunate to have found similarly minded people in the RCA, who provided me with valuable feedback and thoughtful discussions, who mentored me and tolerated my rants about our robot’s code quality. The RCA is self organized, so we don’t have anyone telling us what to do, or how to do it. As a result, we do reinvent the wheel a lot, sometimes for worse, but mostly for the better, like with this project.
During this time I’ve not had the best experience with the “professional” C/C++ embedded community. There are too many established developers convinced of their own opinions that won’t stop arguing until they’ve “won” (just ask about using C++ on µCs and bring some 🍿). Together with the growth in amateur interest in embedded software (absolutely not a bad thing), this completely drowned out any worthwhile online discussions on new approaches to embedded software that are different from the “approved” norm. I’m not talking so much about the programming language itself, which is relatively exchangeable for HALs (a rather unpopular opinion), but about HAL design concepts and perhaps most importantly, support tools.
Let me give you an example: ST has committed at least 4-6 engineers to porting its devices to Arm Mbed OS. Good for ST, that’s a lot of money. But: ST only supports 55 of their ~1100 STM32 targets on Mbed OS, with every single one of them ported by hand. This means at least all startup code and linkerscripts are mostly duplicated for each target and all GPIO signal data is added manually by an unfortunate soul with all the side-effects of manual labor. That’s insane, as you’ve seen above, ST is already maintaining and using this data already to generate code with CubeMX. How is this not automated?
Fortunately, in the last few years there was some significant progress in enabling (new) programming languages on embedded, like MicroPython, Javascript runtimes and perhaps the most significant of them: Embedded in Rust. I’ve been particularly impressed with the progress of the community surrounding @japaricious, who are currently tackling some very hard issues, like IO signal grouping or safe DMA APIs. I’ve kinda written this blog post for them, since I think they are best organized to actually use it and they don’t seem afraid to tackle these issues. (Your move, C++ people!)
For the last 2 years Fabian Greif and I have been working on a secret project called modm: a toolkit for data-driven code generation. In a nutshell, we feed detailed hardware description data for almost all AVR and STM32 targets into a code generator to create a C++ Hardware Abstraction Layer (HAL), startup & linkerscript code, documentation and support tools.
This isn’t exactly a new idea, after all very similar ideas have been floating around before, most notably in the Linux Kernel with its Device Tree (DT) effort. In fact, modm itself is based entirely on xpcc which matured the idea of data-driven HAL generation in the first place.
However, for modm we focused on what goes on behind the scenes: how to acquire detailed target description data and how to use it with reasonable effort. We now have a toolbox that transcends its use as our C++ HAL generator and instead can be applied generically to any project in any language (*awkwardly winks at the Rust community*). That’s pretty powerful stuff.
So let me first ease you into this topic with some historic background and then walk you through the data sources we use and the design decisions of our data engine. All with plenty of examples for you to follow along, just stay well clear of those hairy yaks in the distance.
The Origin Story
All the usual suspects in this case were members of the Roboterclub Aachen e. V. (@RCA_eV). Around 2006 the team surrounding Fabian had built a communication library called RCCP for doing remote procedure calls over CAN. Back then the only affordable microcontrollers were AVRs, but neither were they powerful enough to perform all the computations needed for autonomy nor did they have enough pins to interface with all the motors and sensors we stuffed in our robots. So an embedded PC programmed in various languages did all the heavy lifting and talked via CAN to the AVR actuators and sensors.
(It has been passed on for many generations of robot builders, that the embedded PC did a disk check once during its boot process, which rendered the robot unresponsive for a few minutes. Unfortunately it did this during the a Eurobot finals game and we lost due to that. Since then our robots don’t have a kernel in their critical path anymore.)
RCCP was eventually refactored into the Cross Platform Component Communication (XPCC) library and open-sourced on Sourceforge in 2009. Around 2012 when Fabian was leaving us to go work on satellites at the German space agency (DLR), I took over stewardship of the project and moved it over to GitHub where it exists to this day. It’s the foundation of all the RCAs robots.
From AVR to STM32
By the time I joined in 2010, the team had been using C++ on AVRs for years. Around 2012 we finally outgrew the AVRs used to control our autonomous robots and switched over to Arm Cortex-M devices, specifically the STM32 series. So began the cumbersome task of porting the HAL that worked so well on the AVRs to the STM32F1 and F4 families, both of which have much more capable peripherals.
We had inherited a C++ API that passed around static classes containing the peripheral abstraction to template classes wrapping these classes. It’s the clear anti-thesis of polymorphic interface design, almost a form of “compile time duck-typing”:
class GpioB0 {
public: // one class for every GPIO on the device
static void set(bool state);
};
class SpiMaster0 {
public: // one class for every Spi peripheral
static uint8_t swap(uint8_t data);
};
template< class SpiMaster, class ChipSelect >
class SensorDriver {
public:
uint8_t read() {
ChipSelect::set(Gpio::Low);
uint8_t result = SpiMaster::swap(foobar);
ChipSelect::set(Gpio::High);
return result;
}
};
// Hey look, a generic sensor driver
SensorDriver< SpiMaster0, GpioB0 > compass;
uint8_t heading = compass.read();
C++ concepts sure would be useful here for asserting SpiMaster traits. *cough*
This technique resulted in a rather unusual HAL, but when used in moderation it yields ridiculously small binary sizes! And this was absolutely a requirement on our AVRs which wanted to stuff full of control code for our autonomous robots.
The size reduction didn’t so much come from using C++ features like templates, but from being able to very accurately dissect special cases into their own functions. This is particularly useful on AVRs where the IO memory map is very irregular and differs quite a bit between devices. Writing one function to handle all variations at runtime can be more expensive than writing a couple of specialized functions and letting the linker throw away all the unused ones.
But it does have one significant and obvious disadvantage: Our HAL had to have a class for every peripheral you want to use. And adding these classes manually didn’t scale very well with us and it proved an even bigger problem for a device with the peripheral amount and features of an STM32. And so the inevitable happened: we started using preprocessor macros to “instantiate” these peripheral classes, or switched between different implementation with extensive, often nested, #if/#else/#endif trees. It was such an ugly solution.
We also had a mechanism for generating code manually calling a Jinja2 template engine and committing the result, in fact, already since Nov. 2009. It was first used to create the AVR’s UART classes and slowly expanded to other platforms. But it didn’t really scale either because you still had to explicitly provide all the substitution data to the engine, which usually only was the number, or letter, identifying the peripheral.
It wasn’t until 2013 that Kevin Läufer generalized this idea by moving it into our SCons-based build system and collecting all template substitution data into one common file per target, which we just called “The Device File” (naming things is hard, ok?). This made it much easier to generate new peripheral drivers and it even did so on-the-fly during the build process due to being included into SCons’ dependency graph, which eliminated the need for manually committing these generated files and keeping them up-to-date.
First Steps
The first draft of the STM32F407’s device file was assembled by hand and lacked a clear structure. In retrospect, we also had trouble deciding which data goes in the device file and which stays embedded in the templates, but, we didn’t sweat the details, since we had an entire library to refactor and a robot to build.
The major limitation of our system of course was getting the required data and manually assembling it didn’t scale, and so we were stuck in the same bottleneck as before, albeit with a slightly better build process. And then, after researching how avr-gcc actually generate the <avr/io.h> headers, a solution presented itself: Atmel publishes a bunch of XML files called Part Description Files, or PDFs (lolwut?), containing the memory map of their AVR devices, and we just had to reformat this a little bit. Right? If only I knew what I was getting into…
<module name="USART">
<instance name="USART0" caption="USART">
<register-group name="USART0" name-in-module="USART0" offset="0x00" address-space="data" caption="USART"/>
<signals>
<signal group="TXD" function="default" pad="PD1"/>
<signal group="RXD" function="default" pad="PD0"/>
<signal group="XCK" function="default" pad="PD4"/>
</signals>
</instance>
</module>
<module name="TWI">
<instance name="TWI" caption="Two Wire Serial Interface">
<register-group name="TWI" name-in-module="TWI" offset="0x00" address-space="data" caption="Two Wire Serial Interface"/>
<signals>
<signal group="SDA" function="default" pad="PC4"/>
<signal group="SCL" function="default" pad="PC5"/>
</signals>
</instance>
</module>
<module name="PORT">
<instance name="PORTB" caption="I/O Port">
<register-group name="PORTB" name-in-module="PORTB" offset="0x00" address-space="data" caption="I/O Port"/>
<signals>
<signal group="P" function="default" pad="PB0" index="0"/>
<signal group="P" function="default" pad="PB1" index="1"/>
<signal group="P" function="default" pad="PB2" index="2"/>
<signal group="P" function="default" pad="PB3" index="3"/>
<signal group="P" function="default" pad="PB4" index="4"/>
<signal group="P" function="default" pad="PB5" index="5"/>
<signal group="P" function="default" pad="PB6" index="6"/>
<signal group="P" function="default" pad="PB7" index="7"/>
</signals>
</instance>
Excerpt of the ATmega328P.atdf part description file.
It really turned out to be a great, but very much incomplete, source of information about AVRs. Even today, over 4 years later, 110 AVR memory maps are still missing GPIO signal definitions. So I did what any student with too much time on their hands would do: I began to manually assemble the missing information by downloading all existing AVR device datasheets, reading through all of them and collecting the pinouts in a spreadsheet. I then manually reformatted this data into a Python data structure, where it still exists today. Don’t do this! I did get the job done, but I wasted two weeks of my life with this crap and even though I was being really diligent, I still made a lot of mistakes.
Ah, the insanities of youth 🙄
I also wrote a memory map comparison tool, which was really useful for understanding the batshit-insane AVR IO maps. Since the AVR can only address a certain amount of IO memory directly, the hardware engineers have to “compress” (more like “forcefully stuff”) the IO map and this quickly becomes very ugly. For example, the ATtiny*61 series features differential ADC inputs with selectable gains, configurable in 64 combinations, but register ADMUX only has space for 5 bits (MUX0 - MUX4). So Atmel decided to cram MUX5 into register ADCSRB:
Wait, did the ADLAR bit just move around? Nah, must be an illusion. 😒
This memory map comparison tool was vital in understanding how all the AVRs memory maps differ and coming up with strategies on how to map this functionality into our HAL. It’s all about tools, tools, tools, tools!
Peeking into STM32CubeMX
ST maintains the CubeMX initialization code generator, which contains “a pinout-conflict solver, a clock-tree setting helper, a power-consumption calculator, and an utility performing MCU peripheral configuration”. Hm, doesn’t that sound interesting? How did they implement these features, we wondered.
Back in 2013 CubeMX was still called MicroXplorer and wasn’t nearly as nice to use as today. It also launched as a Windows-only application, even though it was clearly written in Java (those “beautiful” GUI elements give it away). Nevertheless, CubeMX indeed is a very useful application, giving you a number of visual configuration editors:
Configuring the USART1_TX signal on pin PB6 on the popular STM32F103RBT.
During installation, CubeMX kindly unpacks a huge plaintext (!) database to disk at STM32CubeMX.app/Contents/Resources/db (on OSX) and even updates it for you on every app launch. This database consists out of a lot of XML files, one for every STM32 device in ST’s portfolio, plus detailed descriptions of peripheral configurations. It really is an insane amount of data.
So I invite you to join me on a stroll through the colorful fields of XML that power the core of the CubeMX’s configurators. I’ll be using the STM32F103RBT, which is a very popular controller that can be found all ST Links and on the Plue Pill board available on ebay for a few bucks.
GPIO Alternate Functions
We start by searching for the unique device identifier STM32F103RBTx in mcu/families.xml (which is >30.000 lines long, btw). The minimal information about the device here is used by the parametric search engine in CubeMX.
<Mcu Name="STM32F103R(8-B)Tx" PackageName="LQFP64" RefName="STM32F103RBTx">
<Core>ARM Cortex-M3</Core>
<Frequency>72</Frequency>
<Ram>20</Ram>
<Flash>128</Flash>
<Voltage Max="3.6" Min="2.0"/>
<Current Lowest="1.7" Run="373.0"/>
<Temperature Max="105.0" Min="-40.0"/>
<Peripheral Type="ADC 12-bit" MaxOccurs="16"/>
<Peripheral Type="CAN" MaxOccurs="1"/>
<Peripheral Type="I2C" MaxOccurs="2"/>
<Peripheral Type="RTC" MaxOccurs="1"/>
<Peripheral Type="SPI" MaxOccurs="2"/>
<Peripheral Type="Timer 16-bit" MaxOccurs="4"/>
<Peripheral Type="USART" MaxOccurs="3"/>
<Peripheral Type="USB Device" MaxOccurs="1"/>
</Mcu>
Following the Mcu/@Name leads us to STM32F103R(8-B)Tx.xml containing what peripherals and how many (mcu/IP/@InstanceName) as well as what pins exists on this package and where and what alternate functions they can be connected to.
<Core>ARM Cortex-M3</Core>
<Ram>20</Ram>
<Flash>64</Flash>
<Flash>128</Flash>
<!-- ... -->
<IP InstanceName="USART3" Name="USART" Version="sci2_v1_1_Cube"/>
<IP InstanceName="RCC" Name="RCC" Version="STM32F102_rcc_v1_0"/>
<IP InstanceName="NVIC" Name="NVIC" Version="STM32F103G"/>
<IP InstanceName="GPIO" Name="GPIO" Version="STM32F103x8_gpio_v1_0"/>
<!-- ... -->
<Pin Name="PB5" Position="57" Type="I/O">
<Signal Name="I2C1_SMBA"/>
<Signal Name="SPI1_MOSI"/>
<Signal Name="TIM3_CH2"/>
</Pin>
<Pin Name="PB6" Position="58" Type="I/O">
<Signal Name="I2C1_SCL"/>
<Signal Name="TIM4_CH1"/>
<Signal Name="USART1_TX"/>
</Pin>
<Pin Name="PB7" Position="59" Type="I/O">
<Signal Name="I2C1_SDA"/>
<Signal Name="TIM4_CH2"/>
<Signal Name="USART1_RX"/>
</Pin>
Each peripheral has a IP/@Version, which leads to a configuration file containing even more data. Don’t cha just love the smell of freshly unpacked data in the morning? For this device’s GPIO peripheral we’ll look for any pins with the USART1_TX signal in the mcu/IP/GPIO-STM32F103x8_gpio_v1_0_Modes.xml file:
<GPIO_Pin PortName="PB" Name="PB6">
<PinSignal Name="USART1_TX">
<RemapBlock Name="USART1_REMAP1">
<SpecificParameter Name="GPIO_AF">
<PossibleValue>__HAL_AFIO_REMAP_USART1_ENABLE</PossibleValue>
</SpecificParameter>
</RemapBlock>
</PinSignal>
</GPIO_Pin>
<!-- ... -->
<GPIO_Pin PortName="PA" Name="PA9">
<PinSignal Name="USART1_TX">
<RemapBlock Name="USART1_REMAP0" DefaultRemap="true"/>
</PinSignal>
</GPIO_Pin>
So USART1_TX maps to pin PB6 with USART1_REMAP1 or pin PA9 with USART1_REMAP0. The STM32F1 series remap signals either in (overlapping) groups or not at all. This is controlled by the AFIO_MAPRx registers, where we can find PB6/PA9 again:
The __HAL_AFIO_REMAP_USART1_ENABLE in the XML is actually just a C function name, and is placed by CubeMX in the generated init code.
void HAL_UART_MspInit(UART_HandleTypeDef* huart)
{
GPIO_InitTypeDef GPIO_InitStruct;
if(huart->Instance==USART1)
{
/* Peripheral clock enable */
__HAL_RCC_USART1_CLK_ENABLE();
/**USART1 GPIO Configuration
PB6 ------> USART1_TX
PB7 ------> USART1_RX
*/
GPIO_InitStruct.Pin = GPIO_PIN_6;
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_HIGH;
HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);
GPIO_InitStruct.Pin = GPIO_PIN_7;
GPIO_InitStruct.Mode = GPIO_MODE_INPUT;
GPIO_InitStruct.Pull = GPIO_NOPULL;
HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);
__HAL_AFIO_REMAP_USART1_ENABLE();
}
}
The IP files do contain a very large amount of information, however, it’s mostly directed at the code generation capabilities of the CubeMX project exporter, and as such, not very useful as stand-alone information. For example, the above GPIO signal information relies on the existence of a __HAL_AFIO_REMAP_USART1_ENABLE() function that performs the remapping. The mapping between the bits in the AFIO_MAPRx registers and the remap groups is therefore encoded in two separate places: these xml files, and the family’s CubeHAL.
The mcu/IP/NVIC-STM32F103G_Modes.xml configuration file, used to configure the NVIC in the CubeMX, exemplifies this quite well: here we see the first 10 interrupt vectors paired with additional metadata (PossibleValue/@Value seems to contain some : separated conditionals for visibility inside the GUI tool).
<RefParameter Comment="Interrupt Table" Name="IRQn" Type="list">
<PossibleValue Comment="Non maskable interrupt" Value="NonMaskableInt_IRQn:N,IF_HAL::HAL_RCC_NMI_IRQHandler:CSSEnabled"/>
<PossibleValue Comment="Hard fault interrupt" Value="HardFault_IRQn:N,W1:::"/>
<PossibleValue Comment="Memory management fault" Value="MemoryManagement_IRQn:Y,W1:::"/>
<PossibleValue Comment="Prefetch fault, memory access fault" Value="BusFault_IRQn:Y,W1:::"/>
<PossibleValue Comment="Undefined instruction or illegal state" Value="UsageFault_IRQn:Y,W1:::"/>
<PossibleValue Comment="System service call via SWI instruction" Value="SVCall_IRQn:Y,RTOS::NONE:"/>
<PossibleValue Comment="Debug monitor" Value="DebugMonitor_IRQn:Y::NONE:"/>
<PossibleValue Comment="Pendable request for system service" Value="PendSV_IRQn:Y,RTOS::NONE:"/>
<PossibleValue Comment="System tick timer" Value="SysTick_IRQn:Y:::"/>
<PossibleValue Comment="Window watchdog interrupt" Value="WWDG_IRQn:Y:WWDG:HAL_WWDG_IRQHandler:"/>
However, their actual position in the interrupt vector table is missing, and so this data cannot be used to extract a valid interrupt table. Instead an alias is used here to pair the interrupt with its actual table position, as defined in the STM32F103xB CMSIS header file.
For example, the WWDG interrupt vector is located at position 16 (=16+0), while the SVCall vector is located at position 11 (=16-5), or 5 positions behind the UsageFault vector:
/*!< Interrupt Number Definition */
typedef enum {
NonMaskableInt_IRQn = -14, /*!< 2 Non Maskable Interrupt */
HardFault_IRQn = -13, /*!< 3 Cortex-M3 Hard Fault Interrupt */
MemoryManagement_IRQn = -12, /*!< 4 Cortex-M3 Memory Management Interrupt */
BusFault_IRQn = -11, /*!< 5 Cortex-M3 Bus Fault Interrupt */
UsageFault_IRQn = -10, /*!< 6 Cortex-M3 Usage Fault Interrupt */
SVCall_IRQn = -5, /*!< 11 Cortex-M3 SV Call Interrupt */
DebugMonitor_IRQn = -4, /*!< 12 Cortex-M3 Debug Monitor Interrupt */
PendSV_IRQn = -2, /*!< 14 Cortex-M3 Pend SV Interrupt */
SysTick_IRQn = -1, /*!< 15 Cortex-M3 System Tick Interrupt */
WWDG_IRQn = 0, /*!< Window WatchDog Interrupt */
// ...
} IRQn_Type;
So keep in mind that this data is not meant to be a sensible hardware description format and it just often lacks basic information that would make it much more useful. Then again, the only consumer of this information is supposed to be CubeMX for its fairly narrow goal of code generation.
Clock Tree
Let’s look at another very interesting data source in CubeMX: the clock configuration wizard:
What’s so interesting about this configurator is that it knows what the maximum frequencies of the respective clock segments are, and more importantly, how to set the prescalers to resolve these issues and this for every device. You surely know where this is going by know. Yup, it’s backed by data, and here is what it looks like rendered with graphviz.
Here is a beautified excerpt from plugins/clock/STM32F102.xml, which only shows the connections highlighted in red. Note how the text in the nodes maps to the Element/@type and Element/@id attributes, and how the Element/Output and Element/Input children declare a (unique) @signalId and which node they are connecting to:
<Tree id="ClockTree">
<!-- HSE -->
<Element id="HSEOSC" type="variedSource" refParameter="HSE_VALUE">
<Output signalId="HSE" to="HSEDivPLL"/>
</Element>
<!-- PLL div input from HSE -->
<Element id="HSEDivPLL" type="devisor" refParameter="HSEDivPLL">
<Input signalId="HSE" from="HSEOSC"/>
<Output signalId="HSE_PLL" to="PLLSource"/>
</Element>
<Tree id="PLL">
<!-- PLLsource MUX source pour PLL mul -->
<Element id="PLLSource" type="multiplexor" refParameter="PLLSourceVirtual">
<Input signalId="HSE_PLL" from="HSEDivPLL" refValue="RCC_PLLSOURCE_HSE"/>
<Output signalId="VCOInput" to="VCO2output"/>
</Element>
<Element id="VCO2output" type="output" refParameter="VCOOutput2Freq_Value">
<Input signalId="VCOInput" from="PLLSource"/>
<Output signalId="VCO2Input" to="PLLMUL"/>
</Element>
<Element id="PLLMUL" type="multiplicator" refParameter="PLLMUL">
<Input signalId="VCO2Input" from="VCO2output"/>
<Output signalId="PLLCLK" to="SysClkSource"/>
</Element>
</Tree>
<!--Sysclock mux -->
<Element id="SysClkSource" type="multiplexor" refParameter="SYSCLKSource">
<Input signalId="PLLCLK" from="PLLMUL" refValue="RCC_SYSCLKSOURCE_PLLCLK"/>
<Output signalId="SYSCLK" to="SysCLKOutput"/>
</Element>
<Element id="SysCLKOutput" type="output" refParameter="SYSCLKFreq_VALUE">
<Input signalId="SYSCLK" from="SysClkSource"/>
<Output signalId="SYSCLKOUT" to="AHBPrescaler"/>
</Element>
<!-- AHB input**SYSclock** -->
<Element id="AHBPrescaler" type="devisor" refParameter="AHBCLKDivider">
<Input signalId="SYSCLKOUT" from="SysCLKOutput"/>
<Output signalId="HCLK" to="AHBOutput"/>
</Element>
<!-- AHB input**SYSclock** output**FHCLK,HCLK,Diviseurcortex,APB1,APB2 -->
<Element id="AHBOutput" type="activeOutput" refParameter="HCLKFreq_Value">
<Input signalId="HCLK" from="AHBPrescaler"/>
<Output to="FCLKCortexOutput" signalId="AHBCLK"/>
<Output to="FSMClkOutput" signalId="AHBCLK"/>
<Output to="SDIOClkOutput" signalId="AHBCLK"/>
<Output to="HCLKDiv2" signalId="AHBCLK"/>
<Output to="HCLKOutput" signalId="AHBCLK"/>
<Output to="TimSysPresc" signalId="AHBCLK"/>
<Output to="APB1Prescaler" signalId="AHBCLK"/>
<Output to="APB2Prescaler" signalId="AHBCLK"/>
</Element>
</Tree>
We still don’t know how CubeMX is able to do it actual calculations, because the clock graph above doesn’t contain any numbers at all. Some digging around later we can trace the Element/@refParameter attribute to the IP/RCC-STM32F102_rcc_v1_0_Modes.xml which contains *drumroll* numbers, and lots of ‘em:
<!-- Les frequences des sources -->
<RefParameter Name="HSE_VALUE" Min="4000000" Max="16000000" Display="value/1000000" Unit="MHz"/>
<!-- frequence PLL -->
<RefParameter Name="VCOOutput2Freq_Value" Min="1000000" Max="25000000" Display="value/1000000" Unit="MHz"/>
<!-- les diviseurs -->
<RefParameter Name="HSEDivPLL" DefaultValue="RCC_HSE_PREDIV_DIV1">
<PossibleValue Comment="1" Value="RCC_HSE_PREDIV_DIV1"/>
<PossibleValue Comment="2" Value="RCC_HSE_PREDIV_DIV2"/>
</RefParameter>
<!-- Les multiplicateurs -->
<RefParameter Name="PLLMUL" DefaultValue="RCC_PLL_MUL2">
<PossibleValue Comment="2" Value="RCC_PLL_MUL2"/>
<!-- ... -->
<PossibleValue Comment="16" Value="RCC_PLL_MUL16"/>
</RefParameter>
<!-- Les frequences des signaux -->
<!-- SYS clock freq de l'output -->
<RefParameter Name="SYSCLKFreq_VALUE" Max="72000000" Display="value/1000000" Unit="MHz"/>
<!-- diviseur AHB 1..512 -->
<RefParameter Name="AHBCLKDivider" DefaultValue="RCC_SYSCLK_DIV1">
<PossibleValue Comment="1" Value="RCC_SYSCLK_DIV1"/>
<PossibleValue Comment="2" Value="RCC_SYSCLK_DIV2"/>
<PossibleValue Comment="4" Value="RCC_SYSCLK_DIV4"/>
<PossibleValue Comment="8" Value="RCC_SYSCLK_DIV8"/>
<PossibleValue Comment="16" Value="RCC_SYSCLK_DIV16"/>
<PossibleValue Comment="64" Value="RCC_SYSCLK_DIV64"/>
<PossibleValue Comment="128" Value="RCC_SYSCLK_DIV128"/>
<PossibleValue Comment="256" Value="RCC_SYSCLK_DIV256"/>
<PossibleValue Comment="512" Value="RCC_SYSCLK_DIV512"/>
</RefParameter>
<!-- AHB out freq -->
<RefParameter Name="HCLKFreq_Value" Max="72000000" Display="value/1000000" Unit="MHz"/>
Did you know that ST is a French-Italian company? Cos those XML comments clearly aren’t in English. 🤔 Well, that and they seem keen on calling it a “devisor” when they really mean “divider”. What is this, I don’t even.
French comments in XML
Anyways, here you can see the RefParameter/@min and RefParameter/@max frequency values as well as prescaler values encoded as PossibleValue/@Comment, which are all used by CubeMX to check and fix your clock tree. That’s pretty amazing actually.
Ok, so I’m not going into the data of their board support packages, because I don’t think any health insurance covers this much exposure to XML, especially not XML containing French comments. But feel free to take a look at your own risk, it’s just waiting there in plugins/boardmanager/boards for your prying eyes.
Let’s move on to how we can extract this data programmatically and use it to bring order to chaos, one example at a time. A bit like the Avengers franchise *drags out blog post to infinity*
Generating Device Files
The goal of finding machine-readable device description data obviously was to write a program to import, clean-up and convert it into a format that’s more agreeable to our use-case of generating a HAL. Ironically the Device File Generator (DFG) started out in mid 2013 with the innocently named commit “Cheap and simple parsing of the XML files”. It’s not cheap and simple anymore.
The DFG started out as a glorified XPath wrapper in xpcc, but then quickly devolved into some messy monster, that pulled in data from all over the place and arranged it without much concept. Back then we were busy building porting the HAL, writing sensor drivers and building robots, so we didn’t approach this problem structurally, and rather fixed bugs when they occurred.
I won’t talk about xpcc’s DFG architecture issues in detail, instead I’ll be showing you the problems it caused us. This way, the lessons learned are more transferable to other format (*cough* Device Tree *cough*), since the device data is immutable whereas the DFG’s architecture is not.
Note that I rewrote the DFG from scratch for modm, so you can have a look at the source code while reading this. I’m continuing to use the STM32F103RBT6 for illustration, but this all works very similarly for all STM32 and AVR devices.
Device Identifiers
We needed a way to identify what device to build our HAL for, and of course we use the manufacturers identifier, since it’s (hopefully) unique. We also needed to split up the identifier string, so that the HAL can query its traits to select what code templates to use. For example, in xpcc we split stm32f103rbt6 into:
stm32 f1 103 r b
{platform}{family}{name}{pin-id}{size-id}
Note how we forgot the t6 suffix. If we compare this with the documentation on the ST ordering information scheme, you’ll see why this was a huge mistake:
Yup, that’s right, we forgot to encode the package type, causing the DFG to select the first device matching STM32F103RB! And that would be the STM32F103RBHx device, since it occurs first in families.xml.
<Mcu Name="STM32F103R(8-B)Hx" PackageName="TFBGA64" RefName="STM32F103RBHx">
<!-- ... -->
<Mcu Name="STM32F103R(8-B)Tx" PackageName="LQFP64" RefName="STM32F103RBTx">
So we actually used the definitions for the TFBGA64 packaged device instead of the LQFP64 packaged device. 🤦 Incredibly this didn’t cause immediate problems, since we first focussed on the STM32F3 and F4 families, whose functionality is almost identical between packages.
However, we did notice some changes when a new version of CubeMX was released which added or reordered devices in families.xml. And then all hell broke loose when I added support for parsing the STM32F1 device family, which couples peripheral features to memory size and(!) pin count:
“32 KB Flash(1)” aka. this table isn’t complicated enough already
If you’re a hardware engineer at $vendor, PLEASE DON’T DO THIS! This is pure punishment for anyone writing software for these chips. PLEASE DO NOT DO THIS! You should not have to query for combinations of identifier traits to get your hardware feature set. Expand your device lineup into new (orthogonal) identifier space instead.
To be fair, the STM32F1 family was the first ST product to feature a Cortex-M processor and they didn’t use this approach for any of their other STM32 families. I forgive you, ST.
So for modm I looked very carefully at how to split the identifier into traits. I made the trait composition and naming transparent to the DFG, it only operates on a dictionary of items, sharing the same identifier mechanism with the AVRs. Since we currently don’t have any information that depends on the temperature range, I left it out for now. Similarly, the device revision is not considered either.
stm32 f1 03 r b t
{platform}{family}{name}{pin}{size}{package}
Note how both the xpcc and modm identifier encodings differ from the official ST ordering scheme. Since we are sharing some code across vendors (like the Cortex-M startup code), we need to have a common naming scheme, at least for {platform} and {family} or the equivalent for other vendors.
Also note that {name} now does not contain part the trailing 1 of the family. This is to prevent the problem in xpcc where the code template authors only checked for the {name} instead of the {family} and {name}, for example, id["name"] == "103" vs. id["family"] == "f1" and id["name"] == "03". This lead to issues when we ported some peripheral drivers to the L1 family (similar to F0/L0, F4/L4 and F7/H7).
Encoding Commonality
You’ve undoubtedly already noticed that the AVR and CubeMX data is quite verbose and noisy. We didn’t want to use this data directly, hence the DFG. However, we wanted to go a step further and cut down on duplicated data, so that we have an easier time verifying the output of the DFG by not having to look through thousands of files, but rather dozens.
At the time of this writing, families.xml contains 1171 STM32 devices, but modm-devices/devices/stm32 only contains 62 device files, that’s ~19x less files than devices.
We observed that ST clusters their devices on their website, in their technical documentation and in their software offerings. The coarsest regular cluster pattern is the family, which denotes the type of Cortex-M code used among other features. The subfamilies are then more or less arbitrarily clustered around whatever combination of functionality ST wanted to bring to market, but the cluster patterns of pin count, memory size and package are very regular and often explicitly called out. We wanted to reflect this in our data structure too.
This STM32F4x9 feature matrix is extremely regular.
The Device Tree format deals with data duplication by allowing data specialization through an inheritance tree and tree inclusion nodes. However, you still have to create one leaf node for every device, so in the best case you’d have one DT per device, or if you moved common data up the inheritance tree, you’d have more files than devices.
We decided instead to merge our data trees for devices within similar enough clusters and then filter out the data for one device on access. We use logical OR (|) to combine identifier traits to declare what devices are merged. You’ll recognize the <naming-schema> from the previous chapter:
<device platform="stm32" family="f1" name="03" pin="c|r|t|v" size="8|b" package="h|i|t|u">
<naming-schema>{platform}{family}{name}{pin}{size}{package}</naming-schema>
<valid-device>stm32f103c8t</valid-device>
<!-- ... -->
<valid-device>stm32f103rbt</valid-device>
This device file for the F103x8/b devices therefore contains all that match the identifier pattern of r"stm32f103[crtv][8b][hitu]". The engine extracting the data set for a single device will first construct a list of all possible identifier strings via the naming schema and the device combinations: 4*2*4 = 32 identifiers in this example. It then filters these identifiers by the list in <valid-device>, since not every combination actually exists. Whatever device file contains the requested identifier string is then used.
The identifier schema does not have to include all traits either, it only has to be unambiguous. For example the AVR device identifier schema does not contain {platform} but we can infer it anyways:
<device platform="avr" family="mega" name="48|88|168|328" type="|a|p|pa">
<naming-schema>at{family}{name}{type}</naming-schema>
It first seems unnecessary to do this reverse lookup, but it gives us a very important property for free: The extractor does not need to know anything about the identifier, and still understands the mapping of string to traits. So passing stm32f103rbt is now understood as stm32 f1 03 r b t. The disadvantage is having to first build all identifier strings, before returning the corresponding device file. However, this mapping can be cached.
The device file can now use the traits as filters by prefixing them with device-. For our example, the device file continues with declaring the core driver instance, which contains the memory map and vector table. The devices here only differ in Flash size, otherwise they are identical:
<driver name="core" type="cortex-m3">
<memory device-size="8" name="flash" access="rx" start="0x8000000" size="65536"/>
<memory device-size="b" name="flash" access="rx" start="0x8000000" size="131072"/>
<memory name="sram1" access="rwx" start="0x20000000" size="20480"/>
<vector position="0" name="WWDG"/>
<vector position="1" name="PVD"/>
<!-- ... -->
<vector position="42" name="USBWakeUp"/>
By applying some simple combinatorics math we can find the minimal trait set that uniquely describes this difference and can push this filter as far up the data tree as possible while still being unambiguous and therefore losslessly reconstructible for all merged device data. This is all done for the sole purpose of optimizing for human readability, so an embedded engineer with some experience can just look at this data and say: “This filter looks too noisy to me, so something is probably is wrong here” 🤓 *sound of datasheet pages flipping*.
Here is an example of what I so dramatically complained about before: The STM32F1 peripheral feature set is coupled to the device’s pin count: F103 devices with just 36 pins have fewer instances of these peripherals:
<driver name="i2c" type="stm32">
<instance value="1"/>
<instance device-pin="c|r|v" value="2"/>
</driver>
<driver name="spi" type="stm32">
<instance value="1"/>
<instance device-pin="c|r|v" value="2"/>
</driver>
<driver name="usart" type="stm32">
<instance value="1"/>
<instance value="2"/>
<instance device-pin="c|r|v" value="3"/>
</driver>
Of course both the pin count and the package influence the number of available GPIOs and signals. The algorithm here detected that using the pin count as a filter is enough to safely reconstruct the tree, so the device-package is missing (it prioritizes traits further “left” in the identifier):
<driver name="gpio" type="stm32-f1">
<!-- ... -->
<gpio device-pin="r|v" port="c" pin="10"/>
<gpio device-pin="r|v" port="c" pin="11">
<signal driver="adc" instance="1" name="exti11"/>
<signal driver="adc" instance="2" name="exti11"/>
</gpio>
<gpio device-pin="r|v" port="c" pin="12"/>
<gpio device-pin="c|r|v" port="c" pin="13">
<signal driver="rtc" name="out"/>
<signal driver="rtc" name="tamper"/>
</gpio>
The device- filter traits are ORed, multiple filters on the same node ANDed, and the nodes themselves ORed together again. Keen observers will point out that this can create overly broad filters which would make for incorrect reconstruction. For these cases we have to create two nodes with the same data, but different filters to avoid ambiguity. Here is an example from the STM32F4{27,29,37,39} device file:
<gpio port="c" pin="3">
<!-- ... -->
<signal device-name="27|37" device-pin="a|i|v|z" af="12" driver="fmc" name="sdcke0"/>
<signal device-name="29|39" device-pin="a|b|i|n|z" af="12" driver="fmc" name="sdcke0"/>
</gpio>
Hm, but that filter does look suspiciously noisy, doesn’t it? This filter pattern is repeated for the sdne[1:0] and sdnwe signals, which all belong to the SDRAM controller in the FMC. And according to this data set they seem to be unavailable for the LQFP100 package? Hm, better call Saul check the datasheets:
Huh, but the signals do exist for the LQFP100 package!?
“FMC: Yes(1)”. Oh, FFS!
I checked with CubeMX and the GPIO configurator doesn’t allow you to set SDRAM signals in the LQFP100 package, and there are no STM32F4[23]7[BN] devices, so everything is fine, I guess? Nothing to see here folks, move along, the filter algorithm encoded this shit correctly. 🙃
Anyways, I like our device file format a lot, since it describes the device’s hardware in such a compact and concise form. However, it doesn’t scale graciously at all for data that shares less commonalities between devices in the current clusters.
Data Pipeline
For my rewrite of the DFG for modm I wanted to improve the correctness of device merges, remove device specific knowledge as much as possible, support multiple output formats and rename less data. I’ve already hinted at solutions to some of these in the previous chapters, so let’s have a proper look at them now.
The DFG has three parts: frontend, optimizer and backend. Here yellow stands for input data, blue for data conversion, red for intermediate representation (IR) and green for output data. I’ve already covered the vendor input data and the device merging in much detail.
All the ugly is in the parser, it reads the CubeMX data in the same manner I’ve described previously, performs plausibility and format checks on it, and finally normalizes it into a simple Python dictionary. This is just mostly mind-numbingly stupid code to write, since you have to XPath query the CubeMX sources, deal with all the edge cases in the results and normalize all data relative to all devices. Ugly to write, ugly to read, but it gets the job done.
Additional curated data gets injected in this step too. The CubeMX data contains a hardware IP version, which seems to correlate loosely to the peripherals feature set, however, I didn’t find it very useful to distinguish between them. So instead I looked up how all peripherals work in the documentation and grouped them again manually. The device file driver/@type name comes from this data.
For example, here we can see that the entire STM32 platform only has three different I2C hardware implementations, one of which only differs with the addition of a digital noise filter.
'i2c': [{
'instances': '*',
'groups': [
{
# This hardware can go up to 1MHz (Fast Mode Plus)
'hardware': 'stm32-extended',
'features': [],
'devices': [{'family': ['f0', 'f3', 'f7']}]
},{
'hardware': 'stm32l4',
'features': ['dnf'],
'devices': [{'family': ['l4']}]
},{
# Some F4 have a digital noise filter
'hardware': 'stm32',
'features': ['dnf'],
'devices': [{'family': ['f4'], 'name': ['27', '29', '37', '39', '46', '69', '79']}]
},{
'hardware': 'stm32',
'features': [],
'devices': '*'
}
]
}]
All names of peripherals, instances, signals are preserved as they are, so that the name matches the documentation. The only exception are names that wouldn’t be valid identifiers in most programming languages. For our STM32F103RBT example, we split up and duplicate these system signals:
SYS_JTCK-SWCLK => sys.jtck + sys.swclk
SYS_JTDO-TRACESWO => sys.jtdo + sys.traceswo
SYS_JTMS-SWDIO => sys.jtms + sys.swdio
The dictionary returned by the parser is then passed onto a platform specific converter that transforms it into the DFGs intermediate representation. Here the raw data is formatted into a glorified tree structure, which has similar semantics to a very restricted form of XML (ie. attributes are stored separately from its children) and annotates each node with the device’s identifier.
Here the memory maps and the interrupt vector table is added to the name="core" driver node we saw before. The raw data already contains the memories and vectors with the right naming scheme, so it’s easy to just add them here.
for section in p["memories"]:
memory_node = core_driver.addChild("memory")
memory_node.setAttributes(["name", "access", "start", "size"], section)
for vector in p["interrupts"]:
vector_node = core_driver.addChild("vector")
vector_node.setAttributes(["position", "name"], vector)
# sort the node children by start address and size
core_driver.addSortKey(lambda e: (int(e["start"], 16), int(e["size"]))
if e.name == "memory" else (-1, -1))
# sort the node children by vector number and name
core_driver.addSortKey(lambda e: (int(e["position"]), e["name"])
if e.name == "vector" else (-1, ""))
I’m adding two sort keys to the core driver node here, to bring the entire tree into canonical order. This an absolute requirement for the reproducibility of the results, otherwise I wouldn’t be able to tell what data changed if the line order came out differently on each invocation.
It’s time to merge the device IRs now. The device clustering is curated manually, by a large list of identifier trait groups. I considered using some kind of heuristic to automate this, but this works really well, particularly for the AVR and STM32F1 devices. It’s difficult to come up with a metric that accurately describes how annoyed I feel when looking at wrongfully merged device files with lotsa noisy filters. 😤
The STM32F103 devices are split into these four groups:
{
'family': ['f1'],
'name': ['03'],
'size': ['4', '6']
},{
'family': ['f1'],
'name': ['03'],
'size': ['8', 'b']
},{
'family': ['f1'],
'name': ['03'],
'size': ['c', 'd', 'e']
},{
'family': ['f1'],
'name': ['03'],
'size': ['f', 'g']
}
In case you’re curious how bad it would be with just one large F103 group, here is a gist with the resulting device file. It’s not as bad as it could be, but still much harder to read.
At this point the merged IR for our F103RBT device basically already looks like the finished device file, including identifier filters:
device <> stm32f103[c|r|t|v][8|b][h|i|t|u]
. driver <name:core type:cortex-m3>
. memory <name:flash access:rx start:0x8000000 size:65536> stm32f103[c|r|t|v]8[h|t|u]
. memory <name:flash access:rx start:0x8000000 size:131072> stm32f103[c|r|t|v]b[h|i|t|u]
. memory <name:sram1 access:rwx start:0x20000000 size:20480>
. vector <position:0 name:WWDG>
...
. vector <position:42 name:USBWakeUp>
. driver <name:i2c type:stm32>
. instance <value:1>
. instance <value:2> stm32f103[c|r|v][8|b][h|i|t|u]
. driver <name:spi type:stm32>
. instance <value:1>
. instance <value:2> stm32f103[c|r|v][8|b][h|i|t|u]
I’ve already described the device file format above, however, one additional testing step is done before the DFG is finished: A copy of every single device file is taken before merging, so that it can be compared with the device files that are extracted from this merged one. This is a brute-force test to make sure the filter algorithms did perform correctly.
On a side note, the conversion from IR to device file format can be performed at any time, so that last merge step is strictly speaking optional. This is useful for debugging but also if you want to output this data in a format that does not support a merge mechanism similar to the device file’s one, like plain JSON.
Using Device Files
So now that we have all this data, let’s have some fun with it. modm-devices comes not only with the DFG but also with a device file parser, which can be used like this:
>>> import modm.parser, glob
>>> devices = {}
>>> for filename in glob.glob("path/to/modm-devices/devices/**/*.xml"):
>>> for device in modm.parser.DeviceParser().parse(filename).get_devices():
>>> devices[device.partname] = device
>>> devices["stm32f103rbt"].properties
{'driver': [{'memory': [{'access': 'rx',
'name': 'flash',
'size': '131072',
'start': '0x8000000'},
{'access': 'rwx',
'name': 'sram1',
'size': '20480',
'start': '0x20000000'}],
'name': 'core',
'type': 'cortex-m3',
... }]
}
There are some built-in convenience functions for accessing some of the common data in the device files:
>>> device = devices["stm32f103rbt"]
>>> device.identifier
OrderedDict([('platform', 'stm32'), ('family', 'f1'), ('name', '03'), ('pin', 'r'), ('size', 'b'), ('package', 't')])
>>> device.has_driver("usart:avr")
False
>>> device.has_driver("usart:stm32")
True
>>> device.get_driver("usart:stm32")
{'instance': ['1', '2', '3'], 'name': 'usart', 'type': 'stm32'}
I’ve also written a short stats script that allows you to compute some very basic information about the device file collection:
$ python3 tools/device/scripts/stats --count
1355 devices
$ python3 tools/device/scripts/stats --driver
{
"ac": 234,
"adc": 1339,
"aes": 133,
"awex": 26,
"bandgap": 8,
"battery_protection": 7,
"bdma": 20,
"bod": 30,
"can": 683,
"ccl": 30,
"cell_balancing": 5,
"cfd": 2,
"charger_detect": 4,
"clk": 45,
"clock": 242,
"comp": 577,
"core": 1355,
...
}
stats also allows you to dump expanded JSON for a prefix of devices and then query that with the tool of your choice to, for example, get all the I2C related signals on port B for the STM32F4 device family. Not sure why you’d want that, but it’s possible.
$ python3 tools/device/scripts/stats --json stm32f4 | jq '[.[] | .device.driver[] | select(.name == "gpio").gpio[] | . as $gpio | .signal[]? | select(.driver == "i2c" and $gpio.port == "b") | ($gpio.port + $gpio.pin + ":" + .name)] | unique'
[
"b10:scl",
"b11:sda",
"b12:smba",
"b3:sda",
"b4:sda",
"b5:smba",
"b6:scl",
"b7:sda",
"b8:scl",
"b8:sda",
"b9:sda"
]
I’ll discuss in more detail how we use the device files in the next blog post about the modm library.
Try it Yourself
The device file as well as the DFG are available on GitHub for you to play with. It automatically downloads and extracts all the raw data into modm-devices/tools/generator/raw-device-data folder.
git clone --recursive --depth=1 https://github.com/modm-io/modm-devices.git
cd modm-devices/tools/generator
# Extract and generate STM32 device data
make extract-data-stm32
make generate-stm32
# Extract and generate AVR device data
make extract-data-avr
make generate-avr
Not everything I described here is fully implemented, for example, the clock graph extractor is just a proof-of-concept for now. modm-devices is also supposed to be a Python package installable via pip, but that’s not implemented yet.
Please help me maintain this project, I only used devices from a few STM32 families, so it’s difficult to judge the correctness of some of this data. If you know of any other machine readable data, please open an issue or preferrably a pull request.
Two more device file checks are currently not implemented: a XML schema validation, and a semantical checker, that verifies the contents consistency. For example, every GPIO signal should be associable with a driver, and no signal name should start with a number (otherwise difficult to map into most programming languages). These are ideas for the future.
With some effort and additional data sources (CMSIS-SVD files for example), directly outputting to Device Tree format should be possible too. I leave that one to the experts though. 😇
Conclusion
It was important to use not to bind this data to any preconceptions of its use by, for example, integrating it tightly into our HAL generator. Instead we’ve very carefully separated modm-devices from our use of it, so that it can stand on its own and be integrated into all sorts of projects by the community. You’re not bound to using this in code either, you can also generate Markdown documentation, or maybe build your own GPIO configurator as a web UI.
You can go and use it as is with its Python DeviceFile interface, however, for larger projects, I’d recommend you write your own wrapper class, that can format the data as you need it. The Device File format may change at any time, so that I can fit in new data or once I don’t like the format anymore, change it completely. So don’t depend on the format directly.
The next few blog posts will be about applying this data in our own modm library, how CMSIS-SVD compares to CMSIS Headers as additional data sources, and what it means to model check your HAL with this data.
On a Personal Note
The last 5 years working on this have been quite a ride. It has completely changed my view on embedded software engineering and it took a while for me understand this different way of thinking. As far as I know, nobody has deployed hardware description methods on such a large and diverse device base. And we’re just getting started.
I’ve been fortunate to have found similarly minded people in the RCA, who provided me with valuable feedback and thoughtful discussions, who mentored me and tolerated my rants about our robot’s code quality. The RCA is self organized, so we don’t have anyone telling us what to do, or how to do it. As a result, we do reinvent the wheel a lot, sometimes for worse, but mostly for the better, like with this project.
During this time I’ve not had the best experience with the “professional” C/C++ embedded community. There are too many established developers convinced of their own opinions that won’t stop arguing until they’ve “won” (just ask about using C++ on µCs and bring some 🍿). Together with the growth in amateur interest in embedded software (absolutely not a bad thing), this completely drowned out any worthwhile online discussions on new approaches to embedded software that are different from the “approved” norm. I’m not talking so much about the programming language itself, which is relatively exchangeable for HALs (a rather unpopular opinion), but about HAL design concepts and perhaps most importantly, support tools.
Let me give you an example: ST has committed at least 4-6 engineers to porting its devices to Arm Mbed OS. Good for ST, that’s a lot of money. But: ST only supports 55 of their ~1100 STM32 targets on Mbed OS, with every single one of them ported by hand. This means at least all startup code and linkerscripts are mostly duplicated for each target and all GPIO signal data is added manually by an unfortunate soul with all the side-effects of manual labor. That’s insane, as you’ve seen above, ST is already maintaining and using this data already to generate code with CubeMX. How is this not automated?
Fortunately, in the last few years there was some significant progress in enabling (new) programming languages on embedded, like MicroPython, Javascript runtimes and perhaps the most significant of them: Embedded in Rust. I’ve been particularly impressed with the progress of the community surrounding @japaricious, who are currently tackling some very hard issues, like IO signal grouping or safe DMA APIs. I’ve kinda written this blog post for them, since I think they are best organized to actually use it and they don’t seem afraid to tackle these issues. (Your move, C++ people!)